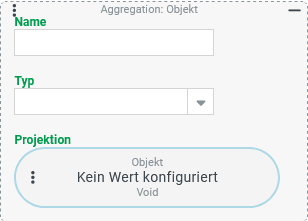
Projektion - Kurzfassung
Zweck: Ermöglicht einfache Berechnungen für einzelne Feldwerte und Aggregationen für Listen von Feldwerten, die optional per Gruppierung als Teilmengen aus einer durch die Suche definierten Grundmenge gebildet werden können.
Tooltip
Verwendung: Die Auswahl für den Typ der Aggregation bestimmt, ob ein Einzelwert oder eine ggf. per Gruppierung ermittelte Wertliste erwartet wird. Die Projektion definiert die Herkunft des Einzelwerts bzw. der zu aggregierenden Werte.
Parameter:
Name definiert optional den Titel einer Ausgabespalte (soweit relevant). Per Standard wird der interne Name für den Typ über den statischen Text ' of ' mit dem anwendbaren Namen für die Projektion verknüpft.
Für den Typ muss eine Auswahl aus den folgenden Optionen getroffen werden:
Aggregationsfunktionen für beliebige Datentypen: Anzahl, Anzahl (unterschiedlich), Min, Max, Wenigste
Aggregationsfunktionen für numerische Datentypen: Summe, Durchschnitt
Berechnungsfunktionen für numerische Werte: Absolut, Negieren, Wurzel
Berechnungsfunktionen für Boolesche Werte: Nicht
Berechnungsfunktionen für Text: Länge, Klein(buchstaben), Groß(buchstaben), Trim
Die Projektion bestimmt aus welcher Quelle der Einzelwert oder die zu aggregierenden Werte bezogen werden
Hinweis: Aggregationsfunktionen ignorieren
$null-Werte aus der Projektion. Berechnungsfunktionen liefern$nullals Ergebnis, für$nullals Wert der Projektion.
Der Projektionstyp Aggregation ermöglicht verschiedene einfache Berechnungen (für einzelne Feldwerte) und Aggregationen für Listen von Feldwerten, die optional per Gruppierung als Teilmengen aus einer durch die Suche definierten Grundmenge gebildet werden können.
Die folgende Tabelle teilt die Optionen für den Typ der Berechnung/Aggregation in Kategorien ein und gibt je Typ an, welcher Datentyp jeweils per Projektion unterstützt wird.
Nur die hier als Aggregationsfunktionen zusammengefassten Typen können mehrere Rückgabewerte aus der Projektion verarbeiten und berücksichtigen dabei ggf. Teilmengen aus einer Gruppierung im Kontext der Suche.
Die anderen Berechnungsfunktionen ermöglichen einfache Berechnungen bzw. "Umwandlungen" von Einzelwerten eines bestimmten Datentyps aus der Projektion.
Typ | Funktionsname | Datentyp für | Beschreibung |
|---|---|---|---|
Aggregationsfunktionen | |||
Anzahl |
| beliebig | Anzahl der zu aggregierenden Einzelwerte, die nicht "Kein Wert" ( |
Anzahl (unterschiedlich) |
| Anzahl der unterschiedlichen Einzelwerte, die nicht "Kein Wert" ( | |
Min |
| Minimalwert (nach der Sortierlogik der verwendeten Datenbank für den Datentyp) | |
Max |
| Maximalwert (nach der Sortierlogik der verwendeten Datenbank für den Datentyp) | |
Wenigste |
| Minimalwert (nach der Sortierlogik der verwendeten Datenbank für den Datentyp) | |
Summe |
| numerisch | Summe der zu aggregierenden Einzelwerte |
Durchschnitt |
| Arithmetisches Mittel der zu aggregierenden Einzelwerte, die nicht "Kein Wert" ( | |
Arithmetik (für einzelnen Zahlenwert) | |||
Absolut |
| numerisch | Gibt den Absolutbetrag eines Zahlenwerts zurück |
Negieren |
| Wechselt das Vorzeichen eines Zahlenwerts ( | |
Wurzel |
| Quadratwurzel eines Zahlenwerts | |
Logik (für einzelnen Booleschen Wert) | |||
Nicht |
|
| Kehrt einen Wahrheitswert um ( |
Textverarbeitung (für einzelnen Textwert) | |||
Länge |
|
| Länge einer Zeichenfolge ( |
Klein |
| Gibt eine Zeichenfolge in Kleinbuchstaben wieder | |
Groß |
| Gibt eine Zeichenfolge in Großbuchstaben wieder | |
Trim |
| "Trimmt" (=entfernt) randständige Leerzeichen von einer Zeichenfolge | |
Konfiguration
Parameter | Typ | Beschreibung |
|---|---|---|
Name |
| Der optionale Parameter Name kann verwendet werden, um der Projektion einen (Alias-)Namen zuzuweisen.
|
Typ |
| Der Typ bestimmt welche Art von Aggregation, Berechnung under Umwandlung auf Basis der Projektion vorgenommen werden soll.
►HINWEIS◄ Die Gliederung der obigen Tabelle nach Kategorien ("Aggregationsfunktionen", "Arithmetik", ...) spiegelt sich nicht im Dropdown. |
Projektion |
| Für den Parameter Projektion können grundsätzlich beliebige Projektionen konfiguriert werden, solange diese einen für den Typ zulässigen Datentyp als Rückgabewert liefern und das verwendete Datenbanksystem deren Verwendung im gegebenen Kontext unterstützt.
|
Beispiele für die Umwandlung von Einzelwerten
Arithmetik - Absolut (ABS): Absolutbetrag eines numerischen Felds als Restriktionsprojektion
Das Standardfeld "Zuletzt geändert von" (lastModifierId) für Entitäten beinhaltet in der Regel einen positiven Long-Wert, der der "ID" (id) eines Benutzerkontos (s. Benutzer) entspricht.
Falls allerdings die letzte Änderung an einer Entität im Kontext eines Gastbenutzerkontos (s. Gastbenutzer) vorgenommen wurde, wird dessen "ID" (id) als negativer Wert im lastModifierId-Feld eintragen, um eine Unterscheidung von Benutzern mit derselben ID sicherzustellen.
Im Datengrid einer Übersicht erscheint die "Zuletzt geändert von" Spalte per Standard leer, wenn dieses Feld ein Gastbenutzerkonto referenziert, weil das per Standard als Spaltenprojektion implementierte Nachschlagen des Benutzernamens (s. Subselect Projektion) für negative Referenzen "unproduktiv" ist.
Ohne Rücksicht auf die Anzeige soll die Filterfunktion für diese Spalte so angepasst werden, dass man Filterkriterien für den positiven Long-Wert einer Konto-ID eingeben kann, die greifen egal, ob es sich um Benutzer oder Gastbenutzer handelt.
Konfiguration:
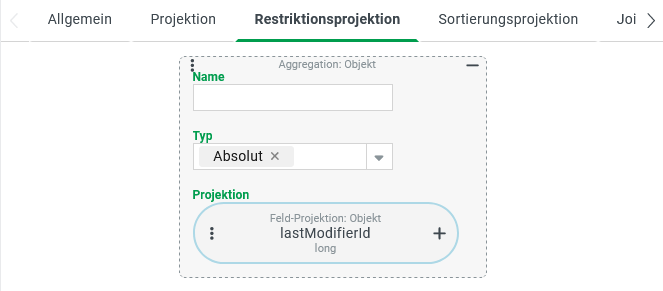
In den Datengrid-Einstellungen für die betreffende Übersicht müssen die Einstellungen für die Spalte "Zuletzt geändert von" (lastModifierId) eingeblendet werden.
Für diese Spalte liegt im Reiter für die Definition der Restriktionsprojektion per Standard keine Konfiguration für eine Projektion vor. Damit gilt die Projektion per Standard auch als Restriktionsprojektion.
Wenn man eine Restriktionsprojektion wie rechts abgebildet konfiguriert, übersteuert diese das Standardverhalten wie folgt:
Anstelle des auf Benutzer zugeschnittenen Textwerts (Schema: {id} - {username}) greift für den Filter als Vergleichswert eine Aggregation mit Typ "Absolut" (
ABS), die hier dazu dient, den aus der Feldprojektion für daslastModifierId-Feld gelesenenLong-Wert vom ggf. vorhandenen Minuszeichen (für Gastbenutzer) zu befreien.Die positiven ID-Werte für Benutzer gibt die Aggregation mit Typ "Absolut" (
ABS) unverändert zurück.Die Charakteristik des Filters passt sich dem numerischen Datentyp an.
►ANMERKUNG◄ Natürlich ist es nicht optimal, dass diese Restriktionsprojektion ein Benutzerkonto und ein Gastbenutzerkonto mit derselben ID nicht voneinander unterscheiden kann. Soweit Überschneidungen der verwendeten IDs überhaupt praxisrelevant sind, bleibt allerdings immer noch die Möglichkeit, die Projektion so anzupassen, dass Benutzer und Gastbenutzer trotzdem deutlich voneinander unterschieden werden können.
Laufzeitbeispiel:
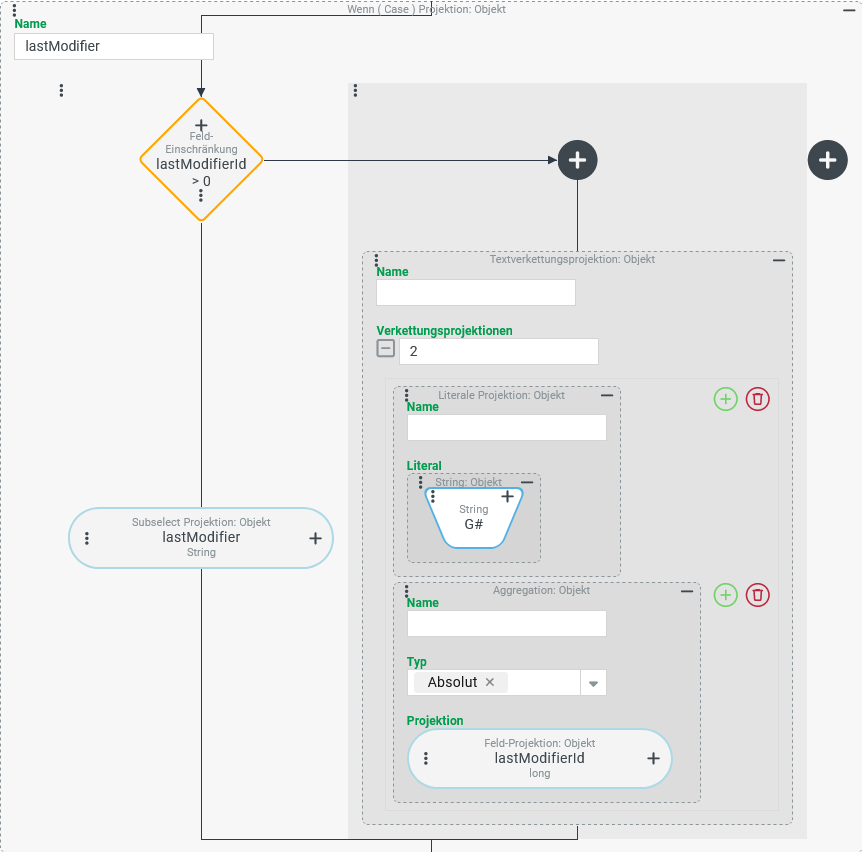
| Der Screenshot links zeigt einen Ausschnitt aus der Spalte "Zuletzt geändert von", für die nicht nur die Restriktionsprojektion (wie oben) angepasst wurde, sondern auch die Projektion, so dass für Gastbenutzer die (positive) ID des Kontos mit dem Präfix "G#" erscheint. Wie der Filterausdruck ( ►ANMERKUNG◄ Die Projektion verwendet eine Wenn ( Case ) Projektion (s. Screenshot unten), die den Anzeigetext für Referenzen auf Gastbenutzer im rechten Zweig der Fallunterscheidung durch eine einfache Textverkettungsprojektion zusammenstellt. Dabei kommt wiederum eine Aggregation mit dem Typ "Absolut" ( |
| |

Arithmetik - Negieren (NEG): Negieren von Zahlenwerten (Vorzeichenumkehr)
Die Positionen eines benutzerdefinierten Entitätstyps "Konto" (s. Eigene Typdefinitionen) dienen zur Erfassung von Ein- und Auszahlungen, die unabhängig von ihrem Typ immer als positive Zahlenwerte in einem Feld "Zahlbetrag" (payment.value) gepflegt werden. Ein zugehöriges Textfeld "Zahlungstyp" (paymentType) dient der weiteren Klassifizierung des Vorgangs.
Per Konvention sollen Auszahlungen über Schlüsselwerte für den "Zahlungstyp" (paymentType) gekennzeichnet werden, die mit dem Buchstaben "R" beginnen.
Über eine Tupel-Suche, die direkt die Positionsebene (AccountLineItem) adressiert, sollen die Salden für jede "Konto"-Instanz so berechnet werden, dass die Summe aller Auszahlungen von der Summer aller Einzahlungen abgezogen wird.
Konfiguration:
Die Tupel-Suche verwendet die zwei rechts abgebildeten Projektionen:
►ANMERKUNG◄ Das Beispiel verwendet die Berechnungsfunktion |
|
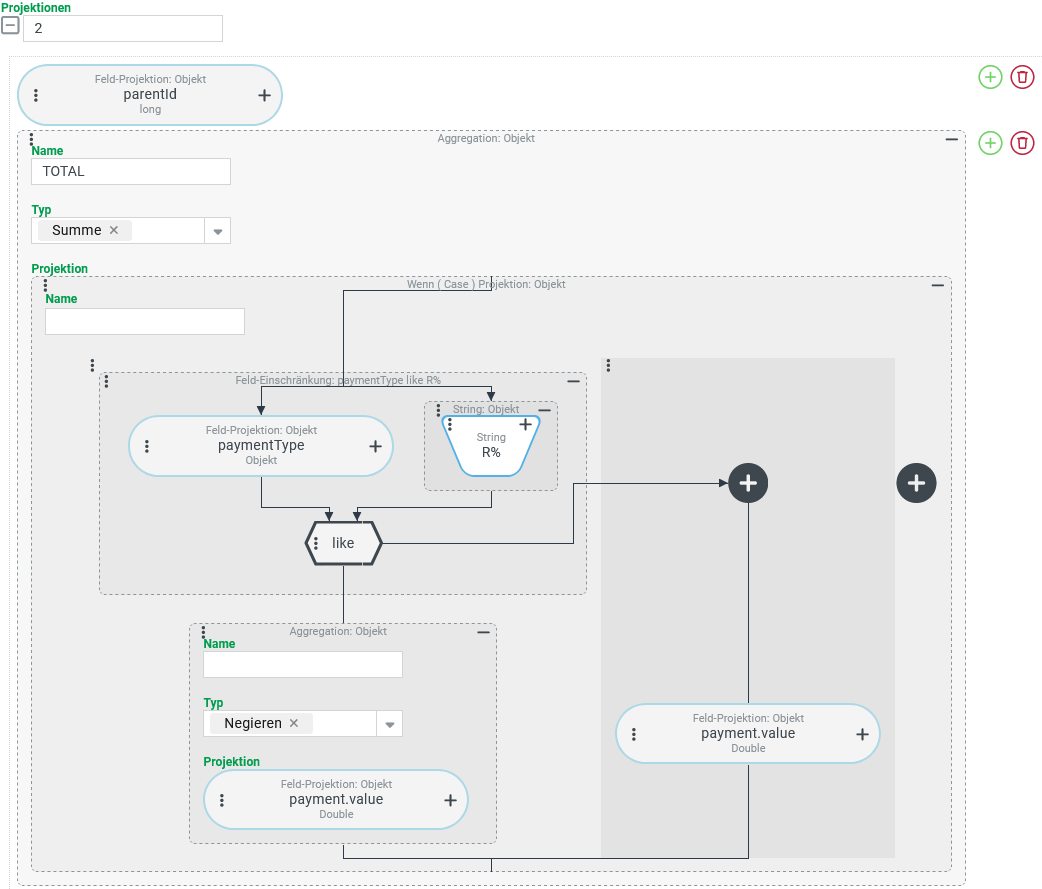
Arithmetik - Wurzel (SQRT): Quadratwurzel
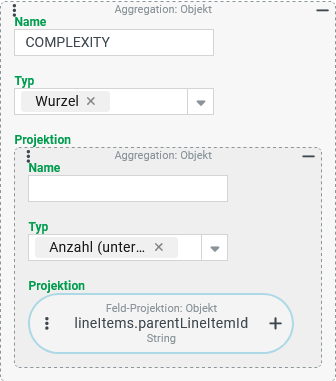
Eine Tupel-Suche für Sendungen soll neben anderen Kennzahlen einen Hinweis auf die Komplexität einer Sendung in einer Spalte COMPLEXITY die Quadratwurzel aus der Anzahl der unterschiedlichen Werte für die "Übergeordnete Position" angeben.
Konfiguration:
Die rechts dargestellte Projektion liefert in Verbindung mit einer - hier nicht gezeigten - Gruppierung der Suche nach dem Feld "ID" (
|
|
Laufzeitbeispiel:
| Die Beispieldaten links zeigen für die Spalte Die Quadratwurzel kommt hier zum Einsatz, da eine Verdopplung der Anzahl von "Übergeordneten Positionen" in der Positionshierarchie nicht doppelte Komplexität bedeuten soll. Eine Vervierfachung aber schon. |
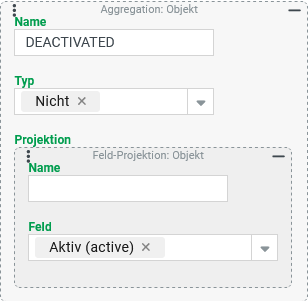
Logik - Nicht (NOT): Logische Verneinung
In einer Tupel-Suche für Benutzer soll das Boolesche Feld "Aktiv" logisch umgekehrt werden, so dass mit der Spaltenbeschriftung wie DEACTIVATED für die Benutzer der Wert $true erscheint, für die das "Aktiv"-Feld den Wert $false enthält und umgekehrt.
Konfiguration:
Die rechts abgebildete Aggregation definiert per Name die Ausgabespalte
|
|
►HINWEISE◄
Das Feld "Aktiv" für Benutzer ist per Definition "nicht nullable", so dass der Rückgabewert der Aggregation in allen Fällen
$trueoder$falselauten wird.Falls für den Rückgabewert der Projektion neben
$trueund$falseauch$nullergeben kann, liefert die Aggregation mit dem Typ "Nicht" (NOT) den Rückgabewert$null, wenn der Originalwert$nullist.
Textverarbeitung – Länge (LENGTH): Textlänge als Filterbedingung
Im der Adressfeld "Kontonummer" (address.accNumber) für Firmen/Mandanten wird per Konvention eine neunstellige Zeichenfolge erwartet.
Eine Suche soll eine Liste aller Firmen/Mandanten liefern, für die diese Konvention für das Adressfeld "Kontonummer" nicht erfüllt ist.
Konfiguration:
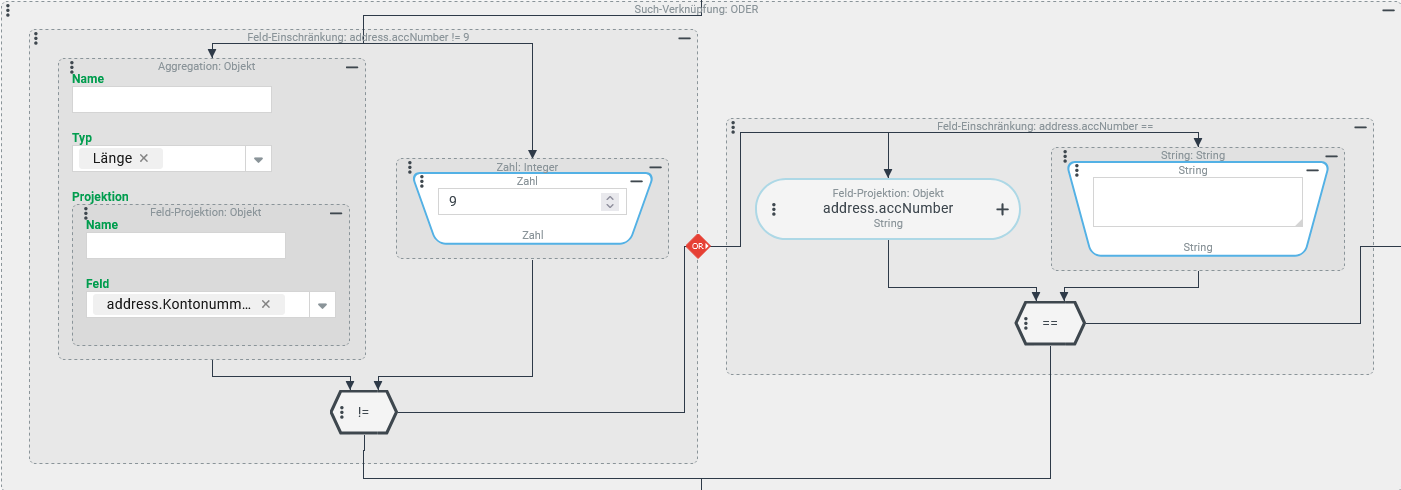
Innerhalb einer ODER-Verknüpfung müssen zwei Instanzen der Feld Einschränkung verwendet werden, um Firmen/Mandanten zu identifizieren, für die das Adressfeld "Kontonummer" (address.accNumber) entweder unapssend oder überhaupt nicht ausgefüllt ist:
Die linke Feld Einschränkung wertet als Prüfwert das Textfeld "Kontonummer" per Aggregation mit dem Typ "Länge" aus, um zu prüfen, ob die Länge einer vorhandenen Zeichenfolge vom Normwert
9abweicht (!=).Die rechte Feld Einschränkung ist erforderlich, um den Fall abzudecken, dass überhaupt keine Angabe für die "Kontonummer" vorliegt.
►WICHTIG◄ Die rechte Feld Einschränkung prüft formal, ob die "Kontonummer" einen Leerstring ("") enthält. Tatsächlich wird diese Bedingung datenbankseitig so umgesetzt, dass sie prüft, ob ein Leerstring oder "Kein Wert" ($null) vorliegt.
Die Aggregation mit Typ "Länge" liefert nur in dem Sonderfall den Wert 0, dass das Adressfeld "Kontonummer" tatsächlich einen Leerstring ("") und nicht "Kein Wert" (
$null) enthält.
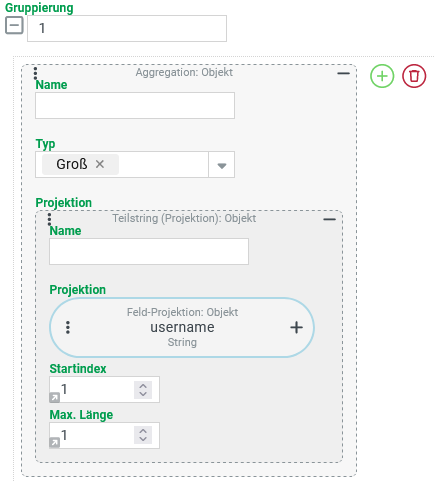
Textverarbeitung – Groß (UPPER): Benutzer nach dem Anfangsbuchstaben im Benutzernamen gruppieren
Eine CSV-Suche soll die Anzahl der Benutzer ausgeben, die sich denselben Anfangsbuchstaben für den "Benutzername" (username) teilen.
Dabei soll nicht zwischen Groß- und Kleinschreibung unterscheiden werden (z. B. {admin,AEINSTEIN}→ A).
Konfiguration:
Als Basis für den Einsatz einer Aggregation mit dem Typ "Anzahl" (s. unten) für die eigentlichen Aggregation der Benutzerkonten wird eine Gruppierung benötigt, die wie rechts abgebildet konfiguriert werden kann:
|
|
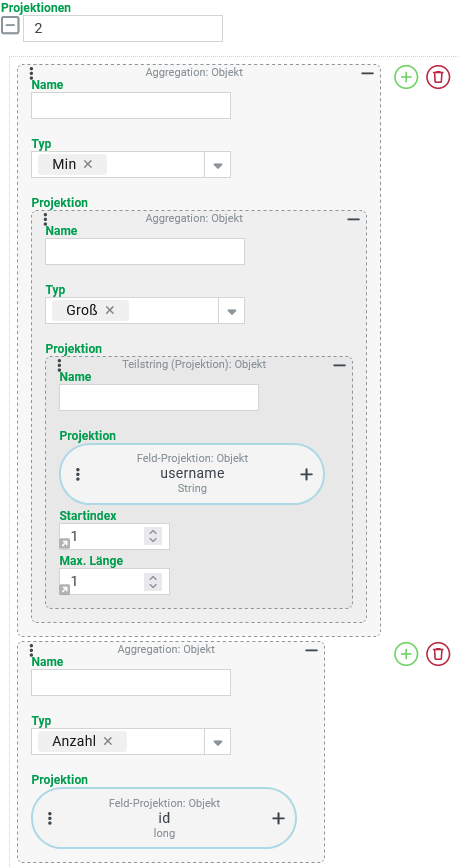
Als Projektionen für die CSV-Suche sollen die folgenden beiden Spalten ausgegeben werden:
|
|
Textverarbeitung – Klein (LOWER): Groß-/Klein-unspezifischer Vergleich
Eine Suche soll alle Benutzer auflisten, für die eine Übereinstimmung zwischen dem Adressfeld "Land" (address.countryCode) mit den ersten beiden Zeichen der internen Kennung für die "Sprache" (locale) übereinstimmt.
Konfiguration:
Die rechts abgebildete Feld Einschränkung ergibt den gewünschten Abgleich:
|
|
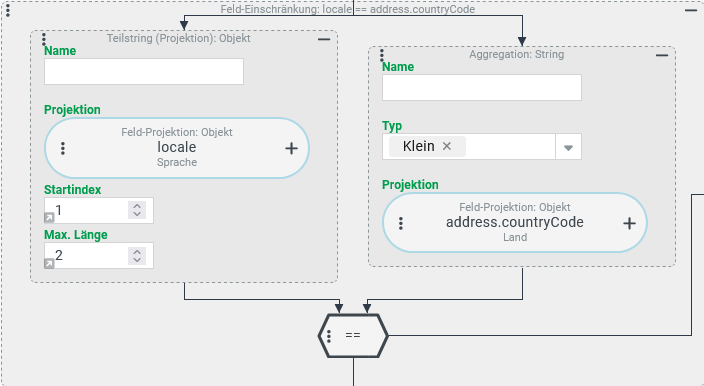
►WICHTIG◄ Eine Aggregation mit dem Typ "Klein" kann im Allgemeinen nicht verwendet werden, um den internen Namen von Aufzählungswerten (hier: Land, Sprache) zu verarbeiten. Das klappt hier nur ausnahmsweise, da die betreffenden Felder für das Benutzerkonto (locale) bzw. die Adresse (countryCode) abweichend vom allgemeinen Standard datenbankseitig als Textfelder behandelt werden. Im Allgemeinen beinhalten Felder, die sich auf Aufzählungen beziehen, datenbankseitig den "Ordinal"-Wert vom Typ Long. Eine Projektion auf ein solches Feld - z. B. das Adressfeld "Anrede" (address.salutation) für einen Benutzer, das sich auf die Dynamische Aufzählung Anrede bezieht - eignet sich dann nicht als Eingabewert für eine Berechnungsfunktionen zur Textverarbeitung in einer Aggregation. Beim Ausführen der Abfrage tritt in der Regel eine Fehlermeldung auf, die auf den Typkonflikt verweist.
Textverarbeitung – Trim (TRIM): Suche nach "ungetrimmten" Texten
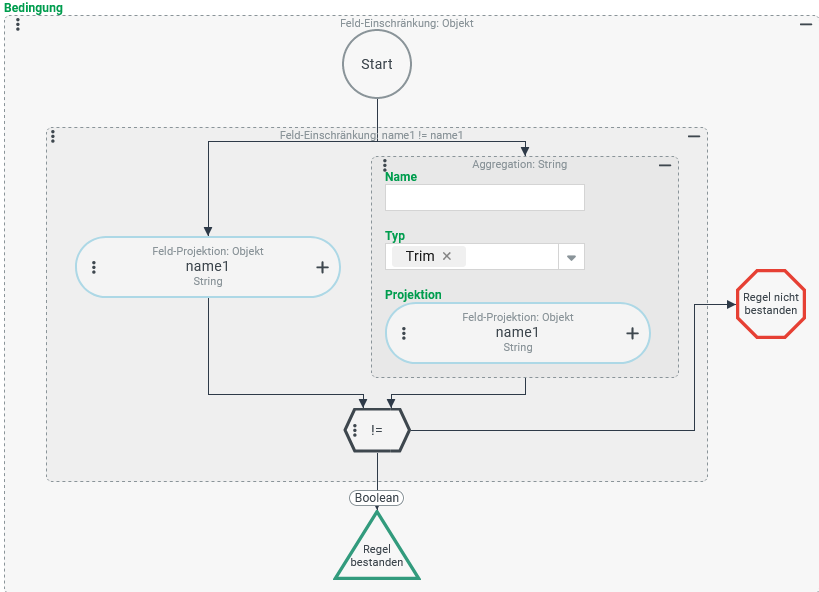
Eine Suche soll Adressen ermitteln, für die als "Name" (name1) "ungetrimmter" Text - also eine Zeichenfolge mit mindestens einem randständigen Leerzeichen - eingegeben wurde.
Konfiguration:
Die rechts abgebildete Bedingung prüft über eine Feld Einschränkung, ob sich der als "Name" (
►HINWEIS◄ Eine Suche mit dieser Bedingung liefert alle Adressen zurück, auf die im Ausführungskontext Zugriff besteht, weil Adressbucheinträge auf sie verweisen. Adressen, die im Kontext anderer Entitäten (z. B. Firmen/Mandanten oder Benutzer) erstellt wurden, sind dagegen nicht Bestandteil des Suchergebnisses, solange der Zugriff nicht über Joins, eine Sub-Suche, o. ä. erfolgt. |
|
Beispiele für Aggregationsfunktionen
Typisches Beispiel: Aggregation von Kennzahlen in einer Suche mit Gruppierung
Eine Tupel-Suche soll drei "statische Kennzahlen" zur Nutzung von Gastbenutzer-Konten durch unterschiedliche Firmen/Mandanten (Spalte: COMPANY) ermitteln:
Anzahl der Gastbenutzer je Firma (Spalte:
GUEST_ACCOUNTS)Summe der durch Gastbenutzer ausgeführten Logins je Firma (Spalte:
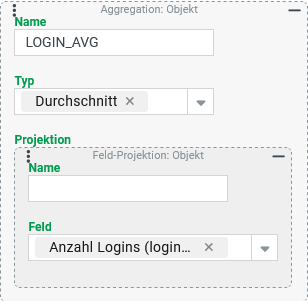
GUEST_LOGINS)Durchschnittliche der Anzahl der je Konto ausgeführten Logins je Firma (Spalte:
LOGIN_AVG)
Laufzeitbeispiel:
Das Beispiel rechts zeigt das Ergebnis einer Tupel-Suche mit folgender Charakteristik:
| |
Konfiguration:
Dei Datenstruktur für Gastbenutzer stellt folgende Merkmale für unsere Statistik bereit:
Das Feld "Firma" (
companyId) ist ein Pflichtfeld für das Gastbenutzer-Konto, das mit einer Referenz auf die "ID" (id) genau eines Firmenkontos (s. Firmen/Mandanten) gefüllt sein muss.Das Feld "Anzahl Logins" (
loginCount) stellt die Anzahl der mit einem Gastbenutzer-Konto ausgeführten Logins als Ganzzahl bereit.
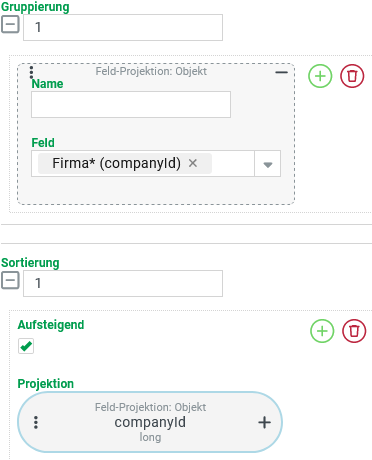
Da unsere Suche Kennzahlen für Gastbenutzer je Firma aggregieren soll, muss für die Suche eine Gruppierung definiert sein:
|
|
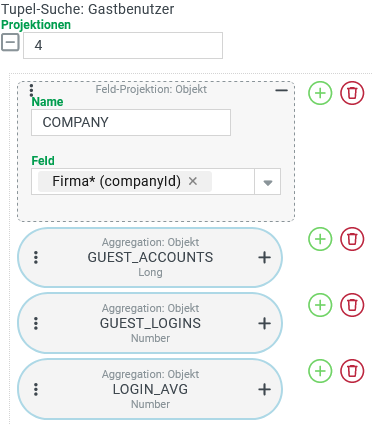
Das Screenshot rechts zeigt eine Übersicht über die für die Tupel-Suche eingerichteten Projektionen, die die Ausgabespalten definieren:
|
|
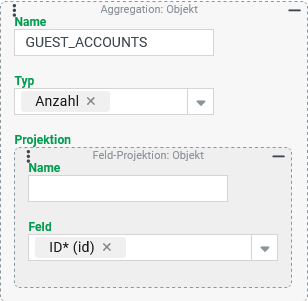
Die Spalte Für den Aggregationstyp "Anzahl" ist die Feldauswahl unerheblich solange sichergestellt ist, dass es nicht "Kein Wert" ( Ohne einen Eintrag für den Parameter Name würde der Titel der Ausgabespalte " |
|
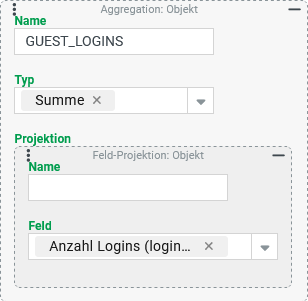
Die Spalte Der Aggregationstyp "Summe" addiert alle gefundenen Zahlenwerte. Ob das Feld in der Projektion für alle aggregierten Gastbenutzer gefüllt ist, spielt für den als "Summe" zurückgegebenen Wert keine Rolle. Ohne einen Eintrag für den Parameter Name würde der Titel der Ausgabespalte " |
|
Die Spalte Der Aggregationstyp "Durchschnitt" bezieht die Summe aller Werte aus der Projektion auf die Anzahl der aggregierten Einzelwerte, die nicht "Kein Wert" ( Ohne einen Eintrag für den Parameter Name würde der Titel der Ausgabespalte " |
|
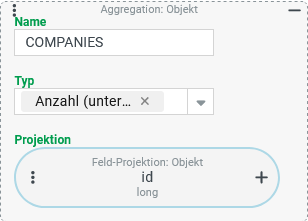
Ungewöhnliches Beispiel: Kennzahlen zu Firmenkonten ermitteln
Eine Tupel-Suche soll drei "statistische Kennzahlen" zu den im System gepflegten Adressen von Firmen/Mandanten ermitteln:
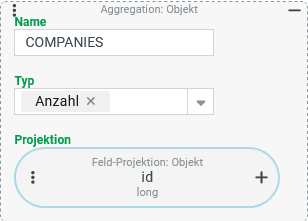
Anzahl aller Firmen/Mandanten (Spalte:
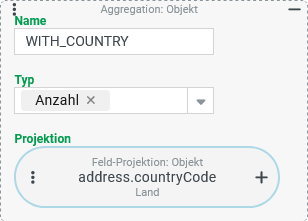
COMPANIES)Anzahl aller Firmen/Mandanten in deren Adresse (
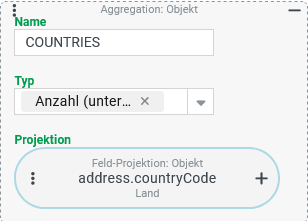
address) ein Land im Feld "Land" (countryCode) ausgewählt ist (Spalte:WITH_COUNTRY)Anzahl der unterschiedlichen Land-Werte im Feld "Land" (
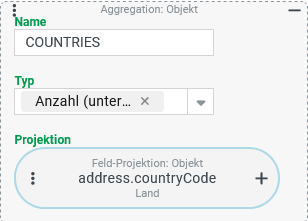
countryCode) in den Adressen von Firmen (Spalte:COUNTRIES)
Laufzeitbeispiel:
Die Kennzahlen für die Auswertung soll alle Firmen "aggregieren", für die im Ausführungskontext Lesezugriff besteht. Das bedeutet:
| |
Konfiguration:
Für die Ausgabespalten der Tupel-Suche werden drei Projektionen vom Typ Aggregation benötigt:
Die Spalte Der Typ "Anzahl" ermöglicht dies in Verbindung mit einer Feldprojektion, die sich auf das Feld "ID" (
|
|
Die Spalte Da der Typ "Anzahl" nur die Werte aus der Projektion berücksichtigt, die nicht |
|
Die Spalte Der Typ "Anzahl (unterschiedlich)" ( ►WICHTIG◄ Der Zustand, dass in der Adresse kein Land angegeben ist, wird nicht mitgezählt. Falls die "Anzahl (unterschiedlich)" den Wert Im Unterschied zum Typ "Anzahl" ist der Typ "Anzahl (unterschiedlich)" grundsätzlich robust gegen das Szenario, dass eine mehrwertige Projektion mehrere Ergebniszeilen je Firma erzeugt (s. folgende Variante). Die Vielfalt der Werte in der Projektion erhöht sich durch eine wiederholte Nennung derselben Werte nicht. |
|
Variante:
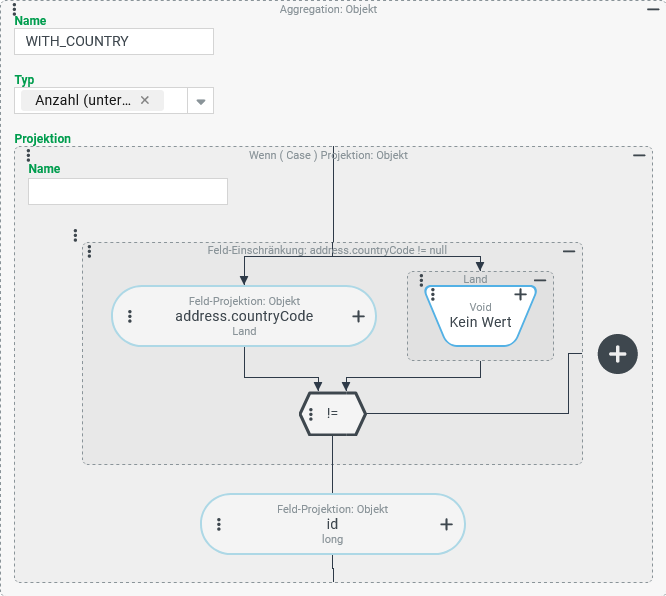
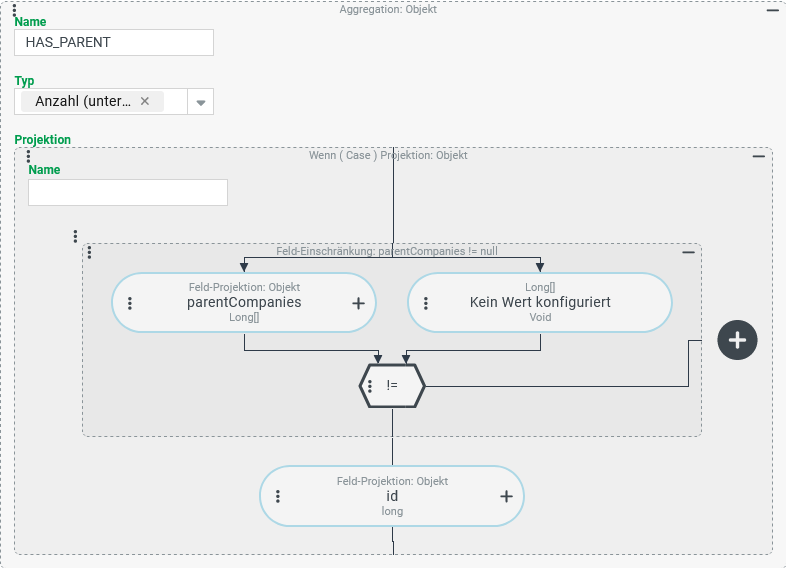
Ausgehend von der bestehenden Konfiguration soll eine weitere Ausgabespalte (HAS_PARENT) hinzugefügt werden, die die Anzahl der Firmen/Mandanten angibt, deren Listenfeld "Übergeordnete Firmen" (parentCompanies) mindestens einen Eintrag enthält.
Angelehnt an die Projektion für die Spalte
Es wichtig zu verstehen, was passiert, wenn man die rechts abgebildete Projektion den bestehenden (s. oben) hinzufügt. Mit denselben Firmendaten wie im obigen Laufzeitbeispiel liefert die erweiterte Tupel-Suche folgendes Ergebnis: |
|
| Ohne den direkten Vergleich zum vorherigen Ergebnis machen die Ergebnisdaten einen durchaus "unverdächtigen" Eindruck. Allerdings liefern die Spalten Warum? Die hinzugefügte Aggregation bezieht sich per Feldprojektion auf ein mehrwertiges Feld (s. a. Datentyp |
Die Aggregationsfunktionen verarbeiten das Ergebnis des "Kreuzprodukts": Die unmittelbar bzw. in einer (1:1)-Relation mit der Firma verknüpften Daten (hier: die Feldwerte für
| |
.svg) ACHTUNG
ACHTUNG .svg) Dieser Ansatz funktioniert formal "fehlerfrei", liefert dabei aber keineswegs die erwarteten Ergebnisse.
Dieser Ansatz funktioniert formal "fehlerfrei", liefert dabei aber keineswegs die erwarteten Ergebnisse.
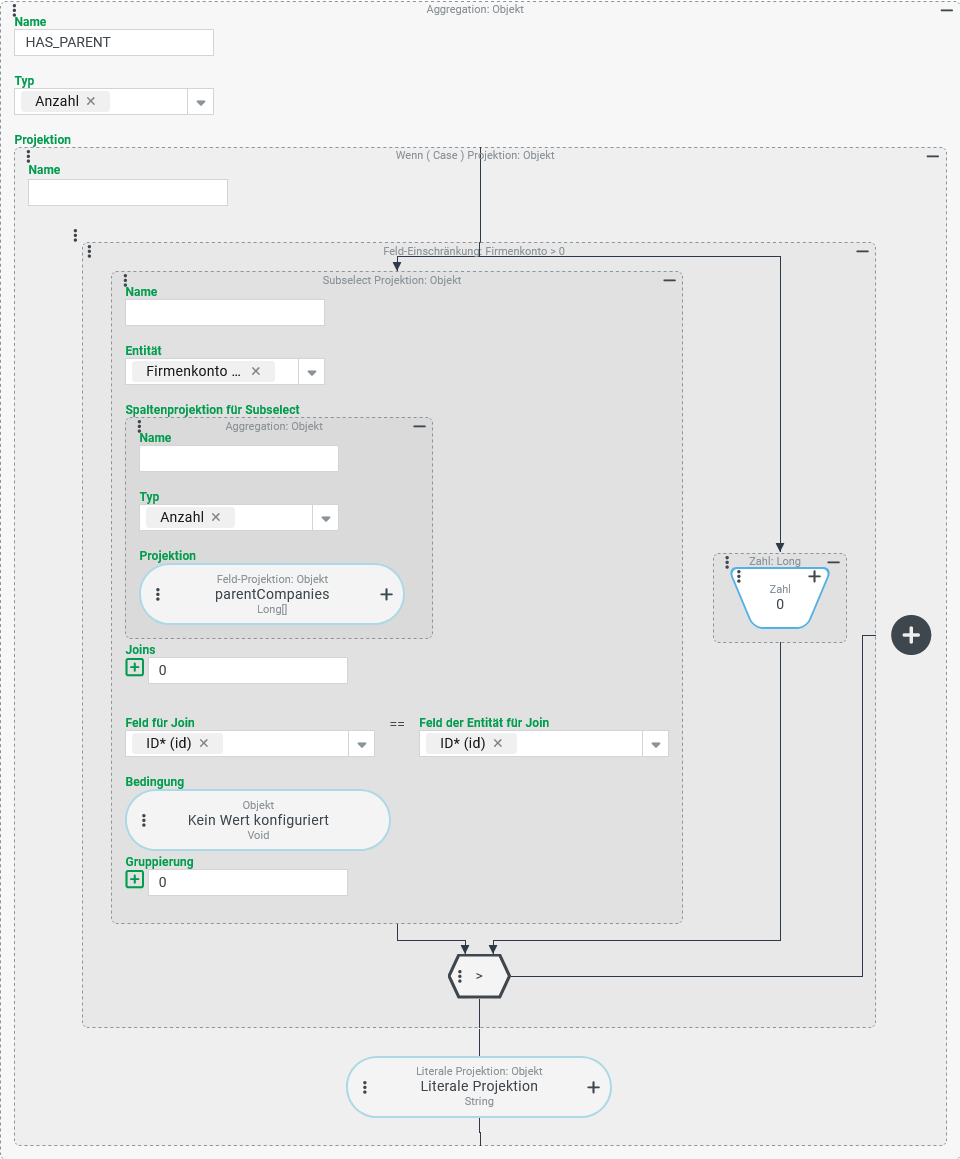
Die folgende Konfiguration für die HAS_PARENT-Spalte verhindert die Multiplikation der Ergebniszeilen vor der Aggregation und sorgt dafür, dass die Suche insgesamt korrekte Daten liefert:
 ACHTUNG Falls das verwendete Datenbanksystem die Verwendung der Subselect Projektion innerhalb einer Aggregationsfunktion nicht unterstützt, tritt eine Fehlermeldung auf. Dies ist z. B. für MSSQL der Fall (s. "Alternative Konfiguration" weiter unten).
ACHTUNG Falls das verwendete Datenbanksystem die Verwendung der Subselect Projektion innerhalb einer Aggregationsfunktion nicht unterstützt, tritt eine Fehlermeldung auf. Dies ist z. B. für MSSQL der Fall (s. "Alternative Konfiguration" weiter unten).
Konfiguration:
Eine Aggregation mit dem Typ "Anzahl" soll alle Firmen/Mandanten zählen, die über mindestens eine übergeordnete Firma verfügen. Die Projektion muss zu diesem Zweck genau dann einen beliebigen von "Kein Wert" (
|
|
Alternative Konfiguration:
Nachdem nicht jedes Datenbanksystem den Einsatz einer Subselect Projektion innerhalb einer Aggregationsfunktion akzeptiert, soll die folgende Konfiguration zeigen, wie man im gegebenen Anwendungsfall auch ohne Subselect Projektion die gewünschten Ergebnisse erzielen kann.
Im bisherigen Ansatz wurde die Subselect Projektion eingesetzt, um das Multiplizieren von Eingangsdaten ("Kreuzprodukt" {Firmen} x {Übergeordnete Firmen}) für die Aggregationsfunktion zu vermeiden.
Der folgende alternative Ansatz nimmt das Multiplizieren der Eingangsdaten bewusst in Kauf und kompensiert dessen Wirkung durch Anpassungen bei Typ und Projektion für die Aggregationsfunktion.
Spalte | Bisherige Projektion | Umstellung | Angepasste Projektion |
|---|---|---|---|
|
| Bisher konnten die Firmen/Mandanten per Typ "Anzahl" ( Die Aggregation wird jetzt umgestellt, auf den Typ "Anzahl (unterschiedlich)" ( |
|
|
| Die bisherige Aggregation hat den Effekt ausgenutzt, dass eine Aggregation mit dem Typ "Anzahl" ( Stattdessen prüfen wir jetzt innerhalb der Projektion über eine Fallunterscheidung per Wenn ( Case ) Projektion ausdrücklich fest, ob das auszuwertende Adressfeld "Land" ( Für die Aggregation wird der Typ umgestellt auf "Anzahl (unterschiedlich)" ( |
|
|
| Die Projektion für die Spalte An der Vielfalt der Länder änder auch ein Multiplizieren der Eingangswerte für die Aggregation nichts. | unverändert: |
| bisher nicht vorhanden | Die Projektion für die Spalte
|
|