Wertauflöser - Kurzfassung
Zweck: Ersetzt ungültige oder Sonderzeichen innerhalb einer übergebenen URL durch universelle Zeichen
Tooltip
Verwendung: Der URL Enkodierung-Wertauflöser wendet die URL-Kodierung ("Prozentkodierung") auf eine als Eingabewert übergebene Zeichenfolge an.
Hinweis: Falls es sich beim Eingabewert nicht um eine Zeichenfolge handelt, wird stattdessen das String-Abbild verarbeitet. Das Ergebnis kann abhängig vom Kontext (Client/Server) unterschiedlich ausfallen.
Der URL Enkodierung-Wertauflöser wendet die URL-Kodierung ("Prozentkodierung") auf eine als Eingabewert übergebene Zeichenfolge an.
Die URL-Kodierung ersetzt ausgewählte Zeichen in durch zweistellige Hexadezimal-Codes (00-FF), denen jeweils ein Prozentzeichen (
%) vorangestellt wird.Die "enkodierte" Zeichenfolge verwendet nur solche ASCII-Zeichen, die z. B. im String-Wert eines URI-Parameters verwendet werden können, ohne dass es zu Überschneidungen mit syntaktisch relevanten Zeichen der URI (
.,?,/,&,=, usw.) kommt.Durch Gruppen von bis zu drei Hex-Codes können außerdem sämtliche Zeichen des UTF-8-Zeichensatzes kodiert werden.
Einfache Beispiele:
Eingabewert (String) | URL-Enkodierung | Anmerkungen |
|---|---|---|
|
| Das Kaufmanns-Und (&) wird als |
|
| Neben dem Kaumfammns-Und (&) müssen hier auch die umgebenden Leerzeichen per Hex-Wert |
|
| Das Gleichheitszeichen (=) wird als |
|
| Das Leerzeichen erscheint als |
|
| Die deutschen Sonderzeichen (ä, ö, Ü und ß) werden hier durch UTF-8-Codes mit je zwei Hex-Bytes ersetzt. |
|
| Hier wurde eine komplette URL (inkl. Query-Parameter "s" mit einem Wert "API") enkodiert, sodass die Zeichen ":", "/", "?" und "=" durch die zugehörigen ASCII-Hex-Codes ersetzt werden. |
|
| Hier enthält der Parameter-Wert für die Suche bereits URL-Code (für das Leerzeichen im Suchtext "No Code"), sodass das bereits kodierte Prozentzeichen (%) erneut kodiert wird. Anstelle des Leerzeichens erscheint damit die Zeichenfolge |
►WICHTIG◄ Falls es sich beim Eingabewert nicht um eine Zeichenfolge (String) handelt, wird das String-Abbild des Eingabewerts enkodiert. Der Aufbau der Zeichenfolge, die als String-Abbild verwendet wird, hängt einerseits vom Datentyp des Eingabewerts ab. Andererseits kann je Ausführungskontext (Client vs. Server) eine spezifische Abbildungsvorschrift greifen, die ggf. auch Lokalisierungen in der Sprachverwaltung bzw. Firmenspezifische Sprachanpassungen berücksichtigen kann. Die folgende Tabelle verdeutlicht diese Einflüsse an zwei Beispielen:
Konfigurationsbeispiel | Ausführungskontext | String-Abbild | Anmerkungen | ||
|---|---|---|---|---|---|
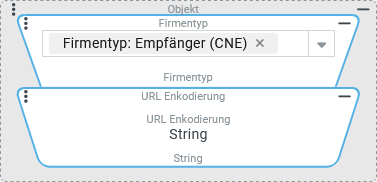
Eingabewert aus der Dynamischen Aufzählung Firmentyp:
| Server | unerheblich |
|
| kein Zeichen "umkodiert" |
Client | Deutsch ( |
|
| Der Umlaut "Ä" im String-Abbild wird durch die zugehörigen UTF-8-Hexadezimalwerte (C3 und A4) in "Prozentkodierung" ersetzt. | |
Englisch ( |
|
| kein Zeichen "umkodiert" | ||
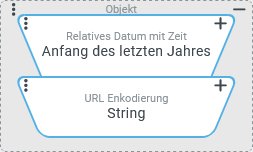
Eingabewert ist ein
| Server | unerheblich |
|
| Standardformatierung des Servers für Zeitangaben (in Original-Zeitzone und UTC jeweils mit Uhrzeit inkl. Millisekunde) mit "umkodierten" Sonderzeichen (Leerzeichen |
Client | Deutsch ( |
|
| Standard Datum-Zeit-Format des Clients gemäß den Lokalisierungen für die Aktuelle Sprache ( | |
Englisch ( |
|
|