Das Steuerungsattribut core:index kann verwendet werden, um in einem Import den zu aktualisierenden Eintrag einer Liste anhand seiner Listenposition zu identifizieren.
Der "Index" zählt dabei beginnend von 0 ganzzahlig aufwärts. Er wird unmittelbar vor jedem Zugriff komplett neu aufgebaut. Dies ist dann besonders wichtig, falls die adressierten Elemente nicht aktualisiert, sondern gelöscht werden sollen.
Häufig beinhaltet die Datenstruktur der Listeneintrags auch ein eigenes Index-Attribut, das z. B. bei typisierten pluralen Attributen auch index heißt.
Das Beispiel rechts zeigt einen XML- Ausschnitt vom
| |
In beiden Fällen kann das jeweilige Indexattribut verwendet werden, um bei einen Import einen bestimmten Listeneintrag anhand seiner Position zu identifizieren.
Allerdings kann für denselben Zweck in beiden Fällen auch das core:index -Attribut für die Identifikation des Listeneintrags genutzt werden.
Beispiel 1: Aktualisieren eines bestimmten Eintrags in einem pluralen Attribut
Für ein Benutzerkonto liegen Adressdaten vor wie im einleitenden Beispiel gezeigt. Per Import soll eine bestimmte der aufgelisteten "Kommunikationsinformationen" aktualisiert werden, nämlich die mit orderIndex=1, die an der zweiten Position erscheint.
Vor dem Import:
| |
Der rechts abgebildete Import verwendet die Aktion
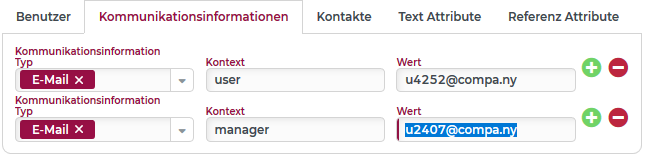
Dem zweiten Eintrag wird eine neue E-Mail-Adresse zugewiesen. | |
Nach dem Import: (Änderung durch Selektion hervorgehoben)
| |
Beispiel 2: Löschen der ersten beiden Einträge für ein Typisiertes plurales Attribut
Für ein Benutzerkonto liegen Adressdaten vor wie im einleitenden Beispiel gezeigt. Per Import sollen die (ersten) beiden Einträge für das plurale Textattribut ACCESS_CODE gelöscht werden.
Der rechts abgebildete Import verwendet die Aktion
►HINWEIS◄ Das wiederholte Einfügen desselben Knotens in einer Importstruktur ermöglicht das Zuordnen einer Integer-Variable als "Pfad" für diesen Knoten, deren wahlweise statisch oder per Zuweisung zur Laufzeit des Profils bestimmter Wert die Anzahl der Iterationen definiert. | |
►ANMERKUNG◄ Man könnte versuchen, im Import auf die beiden zu löschenden Einträge mit unterschiedlichen Werten für core:index (nämlich 0 und 1) zuzugreifen. Dann bliebe der zweite Eintrag bestehen und ein ggf. nachrückender dritter Eintrag würde ggf. gelöscht. Würden die Löschungen in umgekehrter Reihenfolge (erst 1 dann 0) ausgeführt, wäre das Löschen für beide Einträge erfolgreich.