Einstellungen

(1) Eingabeformat prüfen: Wenn dieses Kontrollkästchen aktiviert ist, werden die Quellfelder während des Parsens mit den hinterlegten Formatvorlagen abgeglichen. Verstößt ein Wert gegen die Formatvorlage des Quellfeldes oder überschreitet die Feldlänge, wird ein Fehler generiert. Das Profil wird bei Fehlern nicht sofort beendet, sondern erst nach Phase 2 oder nach 50 Fehlern. Achtung: Diese Funktion beeinträchtigt die Performance und sollte nur bei absoluter Notwendigkeit verwendet werden.
(2) Min/Max-Einstellungen prüfen: Gibt an, ob die Anzahl der Wiederholungen von Feldern und Knoten im Quellbaum geprüft werden soll.
(3) Leerzeichen entfernen (XML wird normalisiert): Leerräume am Anfang und Ende von in Anführungszeichen gesetzten Feldwerten werden entfernt. Beispiel: "33 ";" 44";" 55 "; "66 77 " wird zu "33"; "44"; "55"; "66 77".
(4) Einzelnen Datensatz erzwingen: Gibt an, ob die Daten in einen einzigen Datensatz geparst werden sollen. Ist dieses Kontrollkästchen aktiviert, wird der Parser daran gehindert, mehrere Datensätze zu erstellen.
(5) Parser-Modus: Zeilen- oder spaltenweise Anordnung der Daten in der Datei.
(6) Trennzeichen für Datensätze: Das Trennzeichen zwischen Spalten oder Zeilen (siehe Punkt 5). Üblicherweise wird bei zeilenweiser Anordnung ein Zeilenumbruch (New Line) verwendet. Das Trennzeichen darf im Text vorkommen, der betroffene Text muss dann aber vom CSV-Anführungszeichen (7) umschlossen sein.
(7) CSV-Anführungszeichen: Siehe (6).
(8) Beginnen bei Zeile: Gibt an, bei welcher Zeile die zu verwendenden Daten beginnen. Diese Einstellung dient dazu, eine bestimmte Anzahl von Zeilen zu ignorieren. Der Wert wird verwendet, wenn (5) auf eine zeilenweise Anordnung der Eingabedaten eingestellt ist. Leere Zeilen werden nicht gezählt. Hinweis: Siehe auch Systemvariable VAR_SYS_LINES.
(9) und bei Spalte: Gibt an, bei welcher Spalte die zu verwendenden Daten beginnen. Diese Einstellung dient dazu, eine bestimmte Anzahl von Spalten zu ignorieren. Der Wert wird verwendet, wenn (5) auf eine spaltenweise Anordnung der Eingabedaten eingestellt ist. Leere Spalten werden nicht gezählt.
(10) Lesen bis Zeile: Gibt an, bis zu welcher Zeile die Daten gelesen werden sollen. Die nachfolgenden Zeilen in der Datei werden dann ignoriert.
(11) Zeilen nach Datensatz überspringen: Gibt an, wie viele Zeilen nach einem Datensatz übersprungen werden sollen.
(12) CSV ist Excel-kompatibel (CSV-Export aus Excel): Wenn diese Option aktiviert ist, wird erwartet, dass das CSV-Eingabedokument so formatiert ist, wie es vom Microsoft Excel CSV-Export erzeugt wird.
(13) Bei Zeilenumbruch innerhalb der Zeile weiterlesen: Wenn dieses Kontrollkästchen aktiviert ist, werden Zeilenumbrüche in Spalten entfernt.
Vorher | Hallo du da. |
Nachher | Hallo du da. |
(14) Gleiche Matchcodes existieren: Gibt an, ob identische Datensatztypen mehrfach (verschachtelt) vorkommen, aber nicht zum selben Knoten gehören. Beispiel:
DatensatzA
DatensatzB
...
DatensatzC
...
DatensatzD
DatensatzC
DatensatzD
DatensatzC
...Der erste C-Datensatz soll in einen separaten Knoten geparst werden, die nachfolgenden C-Datensätze jeweils in einen D/C-Knoten. Der CSV-Parser arbeitet hier also ähnlich wie ein EDIFACT-Parser, d.h. er durchläuft die Struktur von oben nach unten und merkt sich, wo er sich befindet. Sobald der untere D/C-Knoten betreten wurde, wird nichts mehr in den oberen C-Knoten eingefügt.
(15) Semantische Prüfungen ausführen: Eingehende Dateien können mit semantischen Regeln geprüft werden. Siehe Abschnitt Semantische Prüfung.
Strukturvorlagen
Siehe Abschnitt Vorlagen für Quell- und Zielstrukturen.
Zeilen ohne Abhängigkeiten
Eine CSV-Datei ist eine Textdatei, die tabellarisch strukturierte Daten enthält und vor allem für den Datenaustausch verwendet wird. Die Daten können zeilen- oder spaltenweise angeordnet sein.
Die erste Tabelle zeigt ein Beispiel für eine zeilenweise Anordnung. Jede Zeile ist ein Datensatz; je mehr Datensätze, desto mehr Zeilen. Die Anzahl der Spalten in der Datei bleibt gleich.
Die zweite Tabelle zeigt ein Beispiel für eine spaltenweise Anordnung. Jede Spalte ist ein Datensatz; je mehr Datensätze, desto länger die Zeilen. Die Anzahl der Zeilen in der Datei bleibt gleich.
Die erste Auflistung zeigt den einfachsten Fall einer CSV-Datei in zeilenweiser Anordnung. Die Datei hat nur einen Datensatztyp, die Felder sind durch ein Semikolon (;) getrennt.
#OrderHeader=OH
OH;Order1
OH;Order2
OH;Order3 Die zweite Auflistung zeigt dieselbe CSV-Datei in spaltenweiser Anordnung.
OH;OH;OH
Order1;Order2;Order3 Beim Mapping wird der Quellbaum auf den Zielbaum abgebildet. Die Erstellung des Quellbaums erfolgt durch den Parser. Der Benutzer kann eigene Knoten und Felder in der Quellstruktur für die Eingabedaten anlegen.
Die folgende Abbildung zeigt die Arbeitsweise des Parsers. Aus den drei Zeilen werden drei Datensätze mit je 2 Feldern. Der Parser zerlegt, beginnend ab der zweiten Zeile, die Eingabedatei in einzelne Datensätze. Anschließend müssen die Zeilen weiter in einzelne Werte zerlegt werden. Um dieses Ziel zu erreichen, muss dem Parser zunächst mitgeteilt werden, dass er eine ganze Zeile als eine Spalte interpretieren soll. Dies wird erreicht, indem der Wert „New Line“ als Trennzeichen im Feld (6) der Parser-Einstellungen eingetragen wird. Anschließend müssen die Zeilen zerlegt werden, indem angegeben wird, wie die einzelnen Werte in einer Zeile getrennt sind. Dies geschieht in den Attributen eines Knotens.
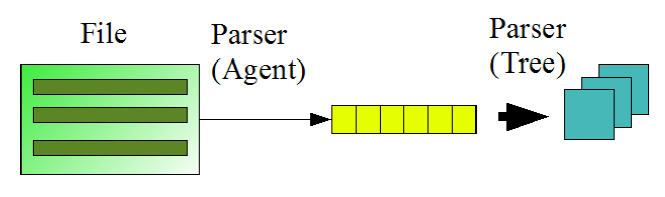
Der folgende Screenshot zeigt die Quellstruktur für die Beispieldatei, unabhängig von der Anordnung der Daten in der Datei.
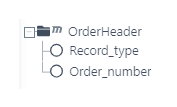
Das Attribut Trennzeichen Spalte/Zeile des Quellstrukturknotens „OrderHeader“ aus dem vorherigen Screenshot gibt das Trennzeichen an, das die Werte in einer Zeile trennt. Da dieser Wert in den Knoten eingetragen wird, sind für unterschiedliche Datensatztypen unterschiedliche Trennzeichen möglich.
Ein Knoten der Quellstruktur wird nur betreten, wenn die gesetzten Bedingungen erfüllt sind. Diese Bedingungen (Matchcodes) können über das Kontextmenü der Quellstrukturknoten definiert werden.
Für einen Knoten können beliebig viele Bedingungen eingetragen werden. Die Bedingungen sind ODER-verknüpft. In unserem Beispiel soll der erste Wert jeder Zeile gegen die Matchcodes geprüft werden. Der Matchcode-Mechanismus ermöglicht es, verschiedene Datensatztypen in einer Eingabedatei zu mischen. Bei Verwendung des Kontrollkästchens (14) kann derselbe Matchcode auch in Unterknoten verwendet werden (Details siehe dort).
Bei Verwendung des CSV-Parsers müssen auch die obersten Knoten die Matchcodes besitzen, die das Auffinden der Unterknoten ermöglichen. Im Gegensatz dazu müssen bei Verwendung des Festlängen-Parsers nur die Unterknoten die Matchcodes haben.
Die folgende Abbildung zeigt die Arbeitsweise des Parsers beim Zerlegen einer Datei in Datensätze mit unterschiedlichen Datensatztypen.
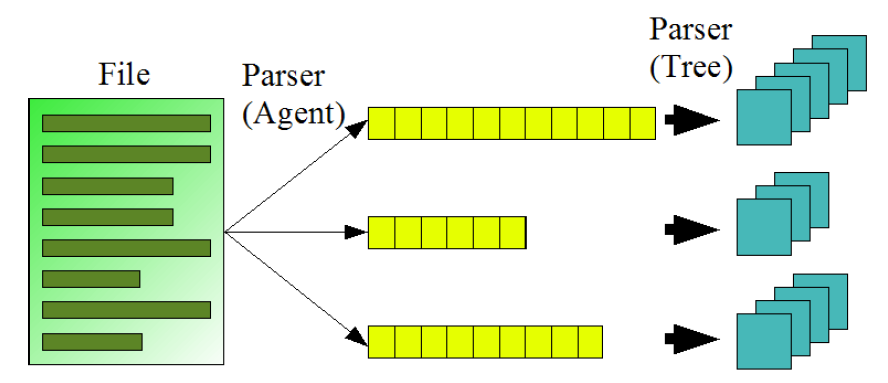
Zeilen mit Abhängigkeiten
Im vorherigen Beispiel gab es keine Abhängigkeiten zwischen den Zeilen in der Eingabedatei, aber normalerweise gibt es sie.
Die folgende Auflistung zeigt das Beispiel einer Datei mit Auftragsköpfen und zugeordneten Auftragspositionen. Der Auftragskopf steht in einer eigenen Zeile, gefolgt von den zugehörigen Auftragspositionen. Die Datei enthält drei Aufträge mit einer, zwei und drei Positionen.
#OrderHeader=OH
#OrderPosition=OP
OH;Order1
OP;Pos1 O1
OH;Order2
OP;Pos1 O2
OP;Pos2 O2
OH;Order3
OP;Pos1 O3
OP;Pos2 O3
OP;Pos3 O3 Eine solche hierarchische Abhängigkeit kann auf zwei verschiedene Weisen abgebildet werden.
Der erste Screenshot zeigt die Quellstruktur für die Beispieldatei. Der Auftragskopf-Knoten und der Positions-Knoten wurden auf der obersten Ebene eingefügt.
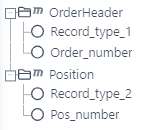
Der zweite Screenshot zeigt eine alternative Quellstruktur für die Beispieldatei. Der Knoten „OrderHeader“ und der Knoten „Position“ wurden in einem übergeordneten Knoten (Parent-Knoten) „Order“ platziert.
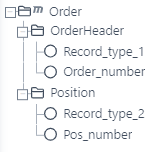
Wichtige Regel für Parent-Knoten
Wenn Sie einen Parent-Knoten verwenden, um andere Knoten zu gruppieren (wie der Knoten „Order“ im zweiten Beispiel), muss sein Attribut Trennzeichen Spalte/Zeile leer bleiben.
Begründung:
Der Parent-Knoten dient lediglich als Container für seine Unterknoten.
Er selbst verarbeitet keine Datenfelder. Die eigentlichen Daten befinden sich in den Unterknoten (
OrderHeaderundPosition).Die Definition eines Trennzeichens für den Container-Knoten würde dazu führen, dass der Parser nach Daten sucht, wo keine vorhanden sind. Dies führt zu unerwarteten Ergebnissen oder Fehlern.
Der Unterschied zwischen den beiden Lösungen besteht darin, dass bei der Quellstruktur im ersten Screenshot für jeden Auftragskopf ein neuer Datensatz erstellt wird, während die Quellstruktur im zweiten Screenshot nur einen einzigen Datensatz erzeugt, der alle Aufträge enthält.
Wenn keine Abhängigkeiten zwischen den Aufträgen zu berücksichtigen sind, ist die erste Lösung zu bevorzugen. Der Grund dafür ist, dass der Parser innerhalb eines Datensatzes arbeitet. Je kleiner die Datenmenge in einem Datensatz ist, desto schneller arbeitet der Parser, obwohl dies nur bei großen Datenmengen eine Rolle spielt.
Sollen in den Ausgabedaten Abhängigkeiten zwischen den Aufträgen hergestellt werden (z. B. das Zusammenfassen der Aufträge in einer Lieferung), muss die zweite Lösung gewählt werden. Bei dieser Lösung werden die drei Aufträge im selben Datensatz gehalten, was es ermöglicht, die Abhängigkeiten zu behandeln (siehe mehr im Abschnitt „Phase 3“).
Immer wenn der erste Knoten der obersten Ebene in der Quellstruktur (im Falle eines CSV-Parsers) betreten wird und es mehrere Knoten auf der obersten Ebene gibt, beginnt der Parser einen neuen Datensatz. Im ersten Beispiel wird daher für jeden Auftragskopf ein neuer Datensatz angelegt. Dadurch entsteht für jeden Auftrag ein Datensatz, der den Auftragskopf und alle zugehörigen Positionen enthält.
Die Reihenfolge der Felder in den Knoten bestimmt, welche Werte der Datenzeilen den Feldern im Quellbaum zugeordnet werden.