Was sind Datenblätter und was ist ihr Sinn?
Beim Parsen werden sogenannte Datenblätter erzeugt. Es wird immer mindestens ein Datenblatt (auch: Record) erzeugt. Hinweis: Für die Anzahl der erzeugten Datenblätter siehe System-Variable VAR_RECORDS.
Strukturierung der Daten
Diese Datenblätter können genutzt werden um auf oberster Ebene die Eingangsdaten und somit indirekt auch die Ausgangsdaten zu strukturieren. Der erste Schritt, wenn man ein Mapping aufbaut, ist immer sich zu überlegen, wie man die Datenblätter beim Parsen aufbauen will. Alles was man im Mappingfenster einstellt/aufbaut, wird pro Datenblatt ausgeführt.
Speichermanagement
Eine weitere Funktion ist das Speichermanagement. Datenblätter können aus dem Hauptspeicher auf die Festplatte auslagern werden (über den Vorgang des sogenannten Swappings). Über diesen Mechanismus kann man die Performance optimieren und auch übergroße Eingangsdateien beherrschen (Verhinderung einer OutOfMemoryException).
Mehrmaliges Ausführen der Antwortwege in Phase 6
Es gibt eine Einstellungsmöglichkeit, mit der die Antwortwege einmal pro Datenblatt und nicht nur einmal pro Profillauf ausgeführt werden können (Option “Pro Datenblatt Antwortwege ausführen” in Phase 2/Erweitert).
Verhalten der verschiedenen Parser
Es gibt einen eigenen Parser mit unterschiedlichem Verhalten für jede Dokumentenart.
Dokumentenart BWA
Der BWA-Parser erkennt automatisch einen Wechsel des Nachrichtentyps, wenn eine Zeile der Eingangsdatei gelesen wird und erzeugt ein neues Datenblatt für diesen Fall.
Dokumentenart CSV
Immer wenn der erste Knoten der obersten Ebene in der Quellstruktur betreten wird und mehrere Knoten auf oberster Ebene vorhanden sind.
Gibt es nur einen Knoten, entsteht immer nur ein Datenblatt. Möchten Sie in diesem Fall aber dennoch, dass zwar nur der ersten Knoten Daten einliest, aber mehrere Datenblätter entstehen, können Sie einen weiteren Knoten einfügen, der sonst keine Funktion hat (also auch keine Daten einliest). Sie können diesen Knoten auch auf inaktiv setzen. Beachten Sie aber, dass die gesetzte Checkbox Gleiche Satzarterkennungen kommen vor dieses Verhalten aushebelt. Zudem können Sie auch die Option “Neues Datenblatt bei Wertänderung” verwenden (siehe Abschnitt unten).
Hinweis: In diesem Zusammenhang ist auch der TokenFileSplitter interessant.
Dokumentenart Cargo-Imp
Der Parser erlaubt pro Eingangsdatei nur genau eine Nachricht. Es wird somit immer genau ein Datenblatt erzeugt.
Dokumentenart Datenbank
Wie Dokumentenart CSV.
Dokumentenart EDIFACT
Für jeden wiederholten Block UNH-UNT oder UNB-UNZ wird ein Datenblatt erzeugt.
Zudem kann mit der Option EDIFACT-Dateien splitten erzwungen werden, dass pro Block ein Job mit einem Datenblatt erzeugt wird.
Dokumentenart Eigene Klasse
Die Daten werden hier direkt an die Integration Unit weitergeleitet. Hier nicht relevant.
Dokumentenart Excel
Wie Dokumentenart CSV. Aber ein zweiter Knoten ist nicht notwendig. Ein Knoten ist ausreichend, um mehrere Datenblätter zu ermöglichen.
Dokumentenart Feste Länge
Immer wenn der erste Knoten der obersten Ebene in der Quellstruktur betreten wird. Auch wenn nur ein Knoten auf oberster Ebene vorhanden ist (also anders als bei Dokumentenart CSV). Hinweis: Die gesetzte Checkbox “Gleiche Satzarterkennungen kommen vor” hebelt dieses Verhalten aus.
Dokumentenart IDoc
Jede Zeile beginnend mit EDI_DC40 erzeugt ein neues Datenblatt.
Dokumentenart JSON
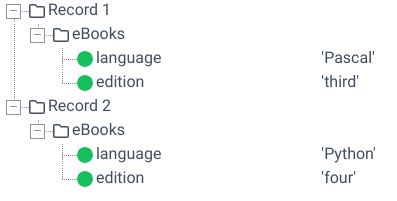
Ist einerseits direkt mit der Funktionalität des Sub-Moduls “Formulare” (Modul “DataCockpit”) verbunden und dort automatisch geregelt. Wird die Dokumentenart eigenständig verwendet und repräsentiert der erste Knoten der Quellstruktur ein Array auf der obersten Ebene der JSON-Datei, dann wird für jeden Wert dieses Arrays ein Datenblatt erzeugt. In allen anderen Fällen wird immer genau ein Datenblatt erzeugt. Beispiel: Gegeben sei folgende Quellstruktur und Eingangsdatei. Dabei würden zwei Datenblätter erzeugt werden.
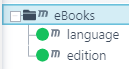
{
"eBooks":[
{
"language":"Pascal",
"edition":"third"
},
{
"language":"Python",
"edition":"four"
}
]
} 
Dokumentenart X12
Es wird für maximal einen Block Daten von Segment ISA-IEA ein Job mit einem Datenblatt erzeugt. Kommen nach dem ersten Tag IEA weitere Daten, dann werden diese ignoriert. Mit der Option X.12 Dateien splitten wird aber für jeden weiteren Block ein neuer Job mit einem Datenblatt erzeugt.
Dokumentenart XML
Phase 2, Option “XML Tag für Datenblatt”.
Bei jedem Vorkommen des Tags wird ein neues Datenblatt angefangen.
Zudem in V4: Steuerung der Datenblatterzeugung über Optionen Knoten für Splitting einfügen und Chunk-Größe.
Zusätzlich relevante Konfigurationen
Bitte beachten Sie jeweils auch die beiden folgenden Optionen für jede Dokumentenart.
Option "Neues Datenblatt erzwingen"
Nur relevant für Dokumentenart CSV und Feste Länge. Siehe Abschnitte Eigenschaften Felder (Quellstruktur) und Eigenschaften Knoten (Quellstruktur).
Option "Erzwinge ein einzelnes Datenblatt"
Siehe jeweilige Dokumentenart (Option ist nicht für alle verfügbar).
Option “Neues Datenblatt bei Wertänderung"
(1) Neues Datenblatt bei Wertänderung: Dies ist eine Quellstrukturfeld-Eigenschaft in Phase 3.
(2) Vorgabewert: Dies ist eine Quellstrukturfeld-Eigenschaft in Phase 3.
Wenn sich alle Feldwerte in den Quellfeldern unterhalb eines Knotens, die die Eigenschaft (1) aktiviert haben, änderten. Ist die Eigenschaft (1) in mindestens einem Eingangsfeld aktiviert, wird der normale Parser-Algorithmus deaktiviert, wenn der jeweilige Parser diese Eigenschaft unterstützt (z. B. CSV). Hinweis: In der Struktur erscheint dann vor dem Feldnamen ein kleiner Pfeil.
Ist in einem Eingangsfeld die Eigenschaft (1) aktiviert und die Eigenschaft (2) gefüllt, wird nur dann ein neues Datenblatt begonnen, wenn sich der Quellfeldwert geändert hat und der neue Quellfeldwert gleich dem in (2) festgelegten Wert ist.
Wichtiger Hinweis: Die Option Pro Datenblatt Antwortwege ausführen und Erzwinge ein einzelnes Datenblatt (siehe oben) können durch die Verwendung von (1) unwirksam werden.
Die folgende Abbildung zeigt die Auswirkung der Eigenschaft (1).
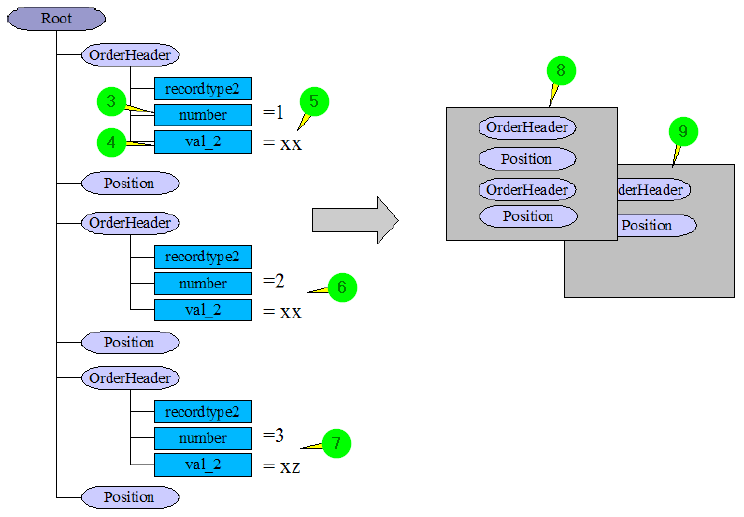
(3) In Feld number in der Quellstruktur wurde die Eigenschaft (1) aktiviert.
(4) In Feld val_2 in der Quellstruktur wurde die Eigenschaft (1) aktiviert.
(5) In den Quelldaten sind die beiden Felder mit den Werten 1 und xx belegt.
(6) In den Quelldaten sind die beiden Felder mit den Werten 2 und xx belegt. Da sich nicht beide Feldwerte von den vorangegangenen Werten unterscheiden, wird kein neues Datenblatt begonnen. Die Knoten werden alle in das erste Datenblatt (8) eingefügt.
(7) In den Quelldaten sind die beiden Felder mit den Werten 3 und xz belegt. Da sich beide Werte von den vorangegangenen Werten unterscheiden, wird ein neues Datenblatt erzeugt und der Knoten in das neue Datenblatt (9) eingefügt. Alle weiteren Knoten werden ebenfalls in das neue Datenblatt eingefügt, bis erneut ein Datenblatt angelegt wird.