The High Availability (HA) architecture is the standard deployment model for TRANSFORM customers. It is also available for SCALE and ACCELERATE customers as an optional upgrade at additional cost. The HA architecture provides a multi-node setup with redundant components across all critical layers, delivering a guaranteed availability of 99.9% per month.
Overview
Unlike the standard architecture, which relies on a single Lobster DATA Platform server, the HA architecture also distributes the load across the working node(s). Each critical component has a redundant counterpart that can take over automatically if the primary component fails. The system is designed so that a single node failure does not cause a complete failure.
The HA architecture is a software-based solution. The Lobster DATA Platform software manages failover and load balancing at the application level. The underlying AWS cloud infrastructure provides the platform (virtual machines, networking, storage) on which the HA system operates, but does not control the application-level failover logic.
The exceptions to this are the DMZ servers and the database. DMZ failover is managed by the AWS DNS service via health checks. Database failover is handled by the AWS Aurora service with automatic replica promotion.
Components
You can find all the information you need at Editions and Sizing
The architecture diagrams can be found here: Architecture diagrams
Failover mechanisms
DMZ failover
DMZ failover is managed at the infrastructure level by the AWS DNS service. Health checks continuously monitor the primary DMZ server. If the primary becomes unresponsive, DNS automatically routes all incoming traffic to the standby DMZ server. No manual intervention is required.
Node failover
Node failover is managed at the application level by the Lobster DATA Platform software. The Node Controller and Working Node(s) continuously monitor each other. If the Node Controller fails, the next Working Node in line detects this and takes over processing. Once the Node Controller comes back online, it automatically resumes control of failover handling.
This is a software-based HA solution. The Lobster software performs the health checks and decides when to trigger a failover or redistribute load. The cloud infrastructure provides the appropriate infrastructure but does not control the failover logic between nodes.
Database failover
Database failover is managed by AWS Aurora PostgreSQL. The primary database instance handles all read and write operations. A synchronized replica is maintained in read-only mode. If the primary instance fails, Aurora automatically promotes the replica to the new primary instance. Data integrity is ensured through synchronous replication.
Shared file system
The HA architecture requires a shared file system that all nodes can access simultaneously. Two options are available:
Standard volume (EFS)
AWS Elastic File System (EFS) is the default shared file system for HA environments. It is suitable for workloads that primarily process larger files (100 KB and above). You can find all the information you need at Editions and Sizing
EFS uses a minimum accounting unit of 4 KB per file access. This means that even if you read a 1 KB file, 4 KB of throughput is consumed. For workloads with many small files, this overhead can significantly reduce effective throughput.
High volume (FSx)
AWS FSx for NetApp ONTAP is available as an upgrade for customers processing large numbers of small files (under 100 KB). It delivers significantly lower latencies and higher IOPS than EFS. You can find all the information you need at Editions and Sizing
Sizing
The HA architecture is available in Sizing M and Sizing L. You can find all the information you need at Editions and Sizing
HA restart and patching behaviour
Detailed information on the maintenance schedule and updates can be found here Maintenance Schedule and Software Update Policy
Info
For information on system availability during software updates and planned maintenance, see Maintenance Schedule
Scalability
Scaling type | Description |
|---|---|
Horizontal scaling | Add an additional Working Node to distribute workload across more processing nodes. Maximum one additional Working Node per environment (production and test). |
Vertical scaling | Upgrade from Sizing M to Sizing L for increased compute and storage capacity on all nodes. |
Storage scaling | Extend shared file system capacity via storage extension packages. Upgrade from Standard Volume (EFS) to High Volume (FSx) for performance-intensive workloads. |
Vertical scaling
Upgrading from one sizing tier to another — for example from Sizing M to Sizing L — increases the compute and storage capacity across all nodes. The upgrade is performed sequentially, node by node. During this process, the Lobster software failover mechanism ensures that a working node is temporarily promoted to Node Controller, maintaining system availability throughout the procedure. Each individual node requires a brief maintenance window, while the overall system remains operational.
During the sequential upgrade process, brief interruptions in response time may occur as individual nodes are restarted and traffic is redistributed. These are expected and transient.
Ideal use cases
The HA architecture is designed for environments where downtime has a direct business impact.
Use case | Description |
|---|---|
24/7 business operations | Near-uninterrupted data integration workflows for enterprises operating around the clock. |
High-volume transaction processing | Environments processing large numbers of transactions where even short outages cause significant backlogs. |
Compliance and disaster recovery | Organisations with strict regulatory requirements for system availability and data protection. |
Mission-critical integrations | Processes where partner systems, APIs or automated workflows depend on continuous availability. |
HA architecture diagrams
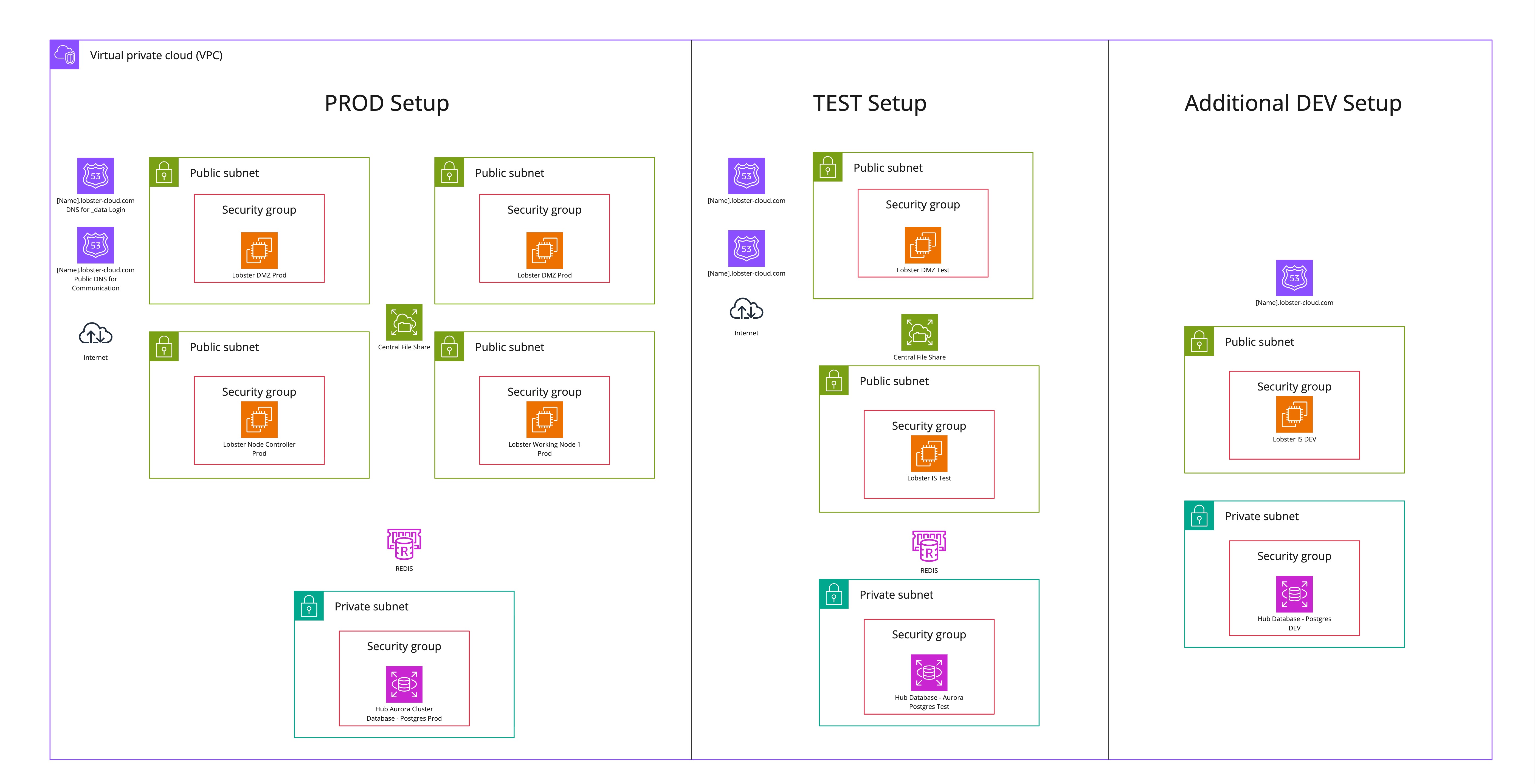
HA setup with standard test system
The following diagram illustrates a standard Lobster Cloud LDP high-availability environment setup with a standard test system. Additionally, a possible DEV system is shown, which is not included in the base setup.
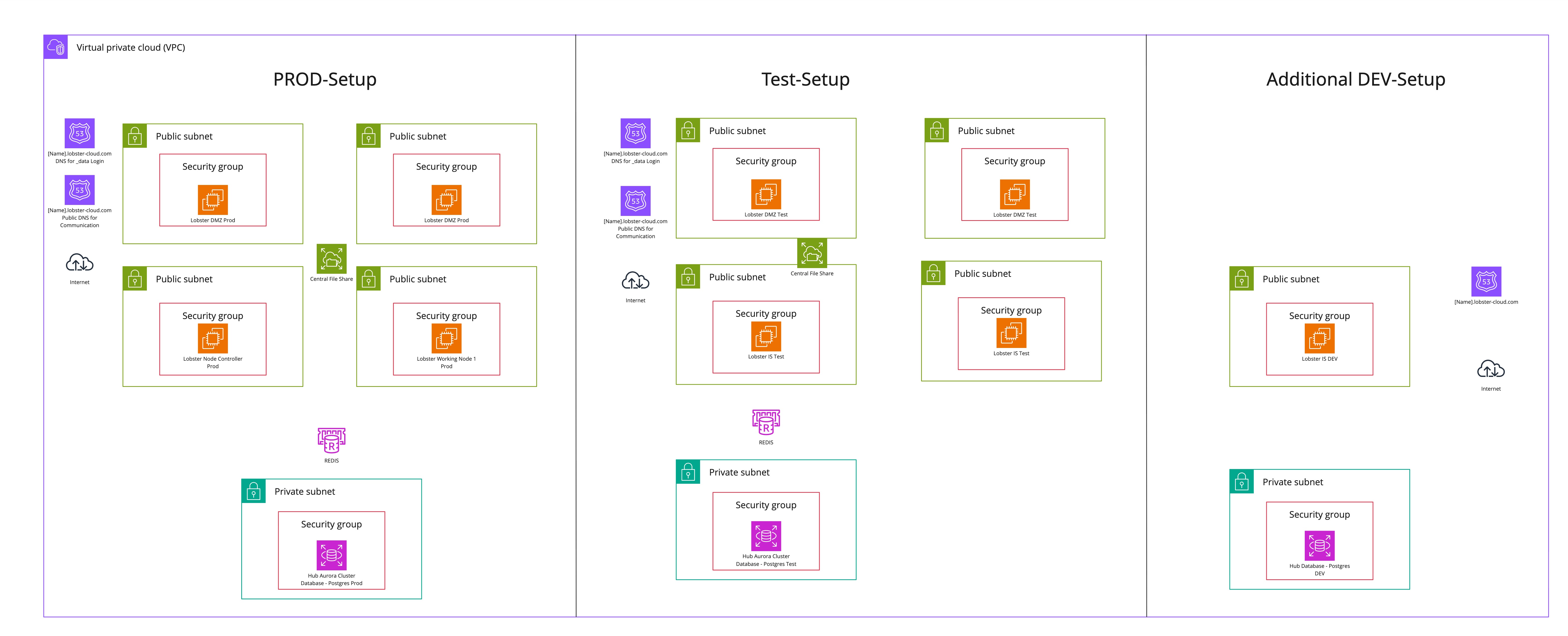
HA setup with HA test system
The following diagram illustrates a standard Lobster Cloud LDP high-availability environment setup with a high-availability test system, which can be added as an optional booking. Additionally, a possible DEV system is shown, which is not included in the base setup.
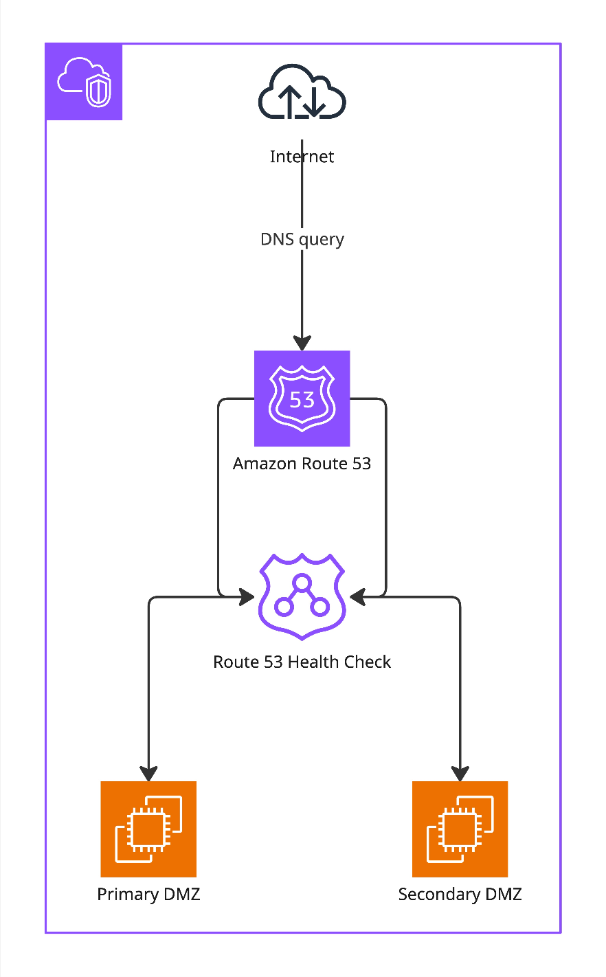
HA-DMZ failover — Amazon Route 53 with health checks
The Lobster Cloud HA setup uses Amazon Route 53 in combination with automated health checks to ensure continuous availability of your DMZ layer. Incoming DNS queries are resolved by Route 53, which continuously monitors the health of both the Primary DMZ and the Secondary DMZ. The health check runs every 30 seconds against port 80. If the Primary DMZ fails three consecutive health checks, Route 53 automatically redirects traffic to the Secondary DMZ without any manual intervention required. Once the Primary DMZ recovers and passes health checks successfully, traffic is automatically routed back. This mechanism ensures that a failure of the primary node is detected and mitigated within a defined, predictable timeframe.
Node failover - healthcheck
The same Route 53 health check mechanism is also used internally to identify the active Node Controller. When logging in from outside via the DMZ, the DMZ determines the active Node Controller and routes the login accordingly. For users accessing the internal system directly behind the DMZ, Route 53 health checks are used to identify the active Node Controller and ensure the login is directed correctly. In both cases, this has no influence on the failover behavior of the system, which is managed entirely by the Lobster software.