Die High-Availability-Architektur (HA) ist das Standard-Bereitstellungsmodell für TRANSFORM-Kunden. Für SCALE- und ACCELERATE-Kunden ist sie als kostenpflichtiges optionales Upgrade verfügbar. Die HA-Architektur bietet ein Multi-Node-Setup mit redundanten Komponenten auf allen kritischen Ebenen. Sie liefert eine garantierte Verfügbarkeit von 99,95 % pro Monat.
Überblick
Die Standard-Architektur basiert auf einem einzelnen Lobster Data Platform-Server. Die HA-Architektur verteilt die Last dagegen auf mehrere Knoten. Jede kritische Komponente hat ein redundantes Gegenstück. Das Gegenstück übernimmt automatisch, wenn die primäre Komponente ausfällt. Das System ist so ausgelegt, dass der Ausfall eines einzelnen Knotens keinen Komplettausfall verursacht.
Die HA-Architektur ist eine softwarebasierte Lösung. Die Lobster Data Platform-Software steuert Failover und Lastverteilung auf Anwendungsebene. Die zugrunde liegende AWS-Cloud stellt virtuelle Maschinen, Netzwerk und Speicher bereit. Die AWS-Cloud steuert jedoch keine Failover-Logik auf Anwendungsebene.
Ausnahmen sind die DMZ-Server und die Datenbank. Amazon Route 53 (der AWS-DNS-Dienst) steuert das DMZ-Failover über Health-Checks. Amazon Aurora PostgreSQL übernimmt das Datenbank-Failover. Dabei stuft Aurora eine Replica automatisch zur primären Instanz hoch.
Weiterführende Informationen
Details zu Komponenten und Sizing finden Sie unter Editions and Sizing.
Siehe HA-Architekturdiagramme.
Failover-Mechanismen
DMZ-Failover
Route 53 steuert das DMZ-Failover auf Infrastrukturebene. Health-Checks überwachen kontinuierlich die Primary DMZ. Wenn die Primary DMZ nicht mehr reagiert, leitet Route 53 den gesamten eingehenden Datenverkehr zur Secondary DMZ um. Ein manueller Eingriff ist nicht erforderlich.
Node-Failover
Die Lobster Data Platform-Software steuert das Node-Failover auf Anwendungsebene. Der Node Controller und die Working Nodes überwachen sich gegenseitig. Wenn der Node Controller ausfällt, erkennt dies der nächste Working Node in der Reihenfolge. Er übernimmt die Verarbeitung. Sobald der Node Controller wieder online ist, übernimmt er die Failover-Steuerung automatisch wieder.
Details zu Health-Checks und Lastverteilung finden Sie unter Load balancing and failover.
Datenbank-Failover
Aurora steuert das Datenbank-Failover. Die primäre Datenbankinstanz verarbeitet alle Lese- und Schreibvorgänge. Aurora hält eine synchronisierte Replica im Read-only-Modus vor. Wenn die primäre Instanz ausfällt, stuft Aurora die Replica automatisch zur neuen primären Instanz hoch. Die synchrone Replikation sichert die Datenintegrität.
Gemeinsames Dateisystem
Die HA-Architektur benötigt ein gemeinsames Dateisystem. Alle Knoten müssen gleichzeitig darauf zugreifen können. Zwei Optionen stehen zur Verfügung:
Standard Volume (EFS)
AWS Elastic File System (EFS) ist das standardmäßige gemeinsame Dateisystem für HA-Umgebungen. Es eignet sich für Workloads, die überwiegend größere Dateien verarbeiten (ab 100 KB). Details finden Sie unter Editions and Sizing.
EFS rechnet jeden Dateizugriff mit mindestens 4 KB ab. Auch beim Lesen einer 1-KB-Datei verbraucht EFS 4 KB Durchsatz. Bei Workloads mit vielen kleinen Dateien kann dieser Overhead den effektiven Durchsatz deutlich reduzieren.
High Volume (FSx)
AWS FSx for NetApp ONTAP ist als Upgrade verfügbar. Es richtet sich an Kunden, die viele kleine Dateien verarbeiten (unter 100 KB). Es liefert deutlich geringere Latenzen und höhere IOPS als EFS. Details finden Sie unter Editions and Sizing.
HA-Verhalten bei Neustart und Patching
Details finden Sie unter Maintenance Schedule und Software Update Policy.
Info
Informationen zur Systemverfügbarkeit während Software-Updates und geplanter Wartung finden Sie unter Maintenance Schedule.
Skalierbarkeit
Skalierungstyp | Beschreibung |
|---|---|
Horizontale Skalierung | Fügen Sie einen zusätzlichen Working Node hinzu, um die Last auf mehr Verarbeitungsknoten zu verteilen. Maximal ein zusätzlicher Working Node pro Umgebung (Produktion und Test). |
Vertikale Skalierung | Upgrade von Sizing M auf Sizing L für mehr Rechen- und Speicherkapazität auf allen Knoten. |
Speicher-Skalierung | Erweitern Sie die Kapazität des gemeinsamen Dateisystems über Storage-Extension-Pakete. Upgrade von Standard Volume (EFS) auf High Volume (FSx) für performance-intensive Workloads. |
Vertikale Skalierung
Ein Upgrade auf eine höhere Sizing-Stufe erhöht die Rechen- und Speicherkapazität auf allen Knoten. Beispiel: ein Upgrade von Sizing M auf Sizing L. Das Upgrade erfolgt sequenziell, Knoten für Knoten. Dabei stuft der Failover-Mechanismus vorübergehend einen Working Node zum Node Controller hoch. Das System bleibt während des gesamten Vorgangs verfügbar. Jeder Knoten benötigt ein kurzes Wartungsfenster.
Während des sequenziellen Upgrades startet das System einzelne Knoten neu und verteilt den Datenverkehr um. Kurze Unterbrechungen der Antwortzeit können auftreten. Diese Unterbrechungen sind zu erwarten und vorübergehend.
Ideale Einsatzszenarien
Die HA-Architektur ist für Umgebungen ausgelegt, in denen Ausfallzeiten direkte geschäftliche Auswirkungen haben.
Einsatzszenario | Beschreibung |
|---|---|
24/7-Geschäftsbetrieb | Nahezu unterbrechungsfreie Datenintegrations-Workflows für Unternehmen mit Rund-um-die-Uhr-Betrieb. |
Transaktionsverarbeitung mit hohem Volumen | Umgebungen mit vielen Transaktionen, in denen schon kurze Ausfälle erhebliche Rückstände verursachen. |
Compliance und Disaster Recovery | Organisationen mit strengen regulatorischen Anforderungen an Systemverfügbarkeit und Datenschutz. |
Geschäftskritische Integrationen | Prozesse, bei denen Partnersysteme, APIs oder automatisierte Workflows von kontinuierlicher Verfügbarkeit abhängen. |
HA-Architekturdiagramme
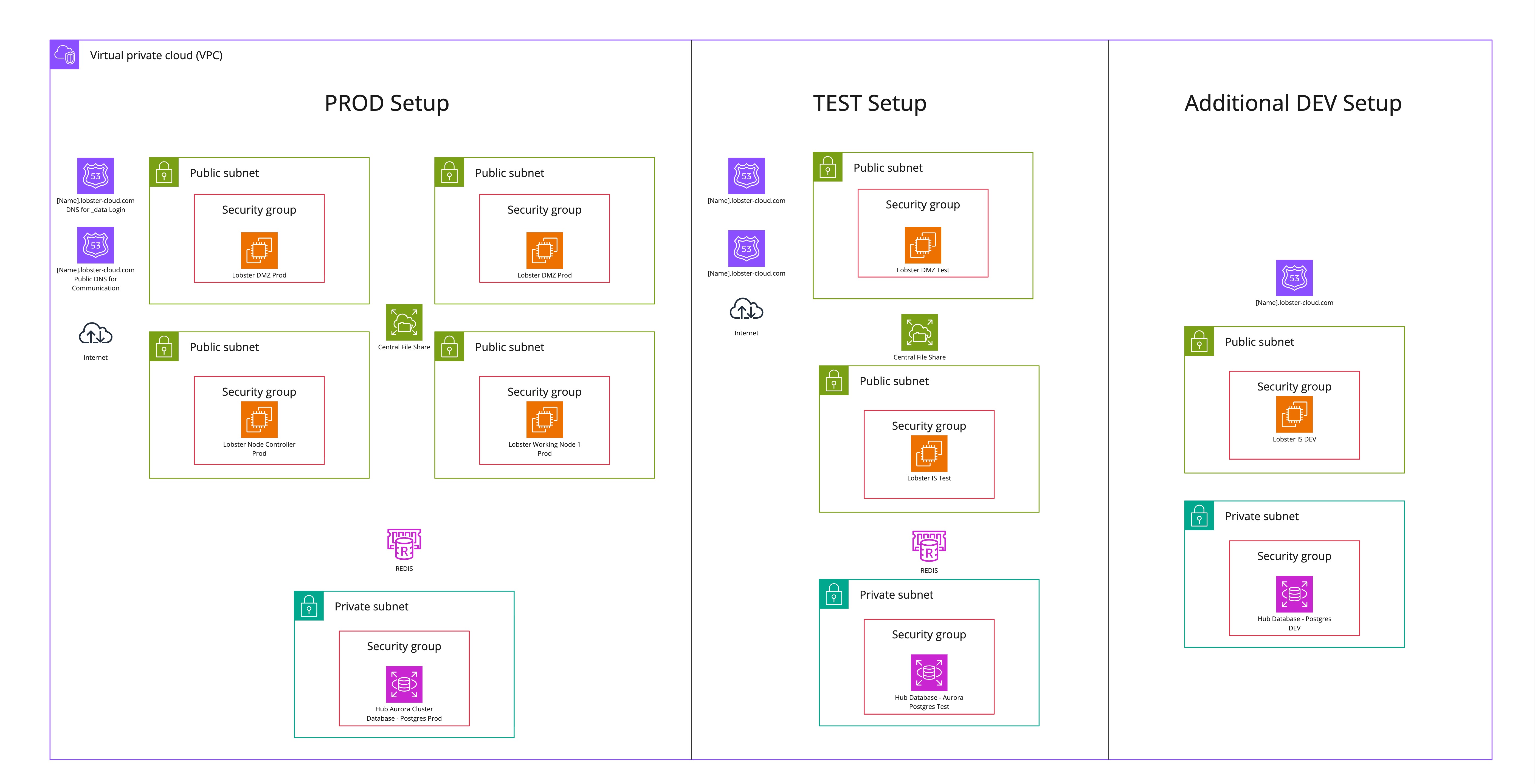
HA-Setup mit Standard-Testsystem
Das folgende Diagramm zeigt eine standardmäßige Lobster Cloud High-Availability-Umgebung mit einem Standard-Testsystem. Das Diagramm zeigt zusätzlich ein optionales DEV-System. Das DEV-System ist nicht im Basis-Setup enthalten.
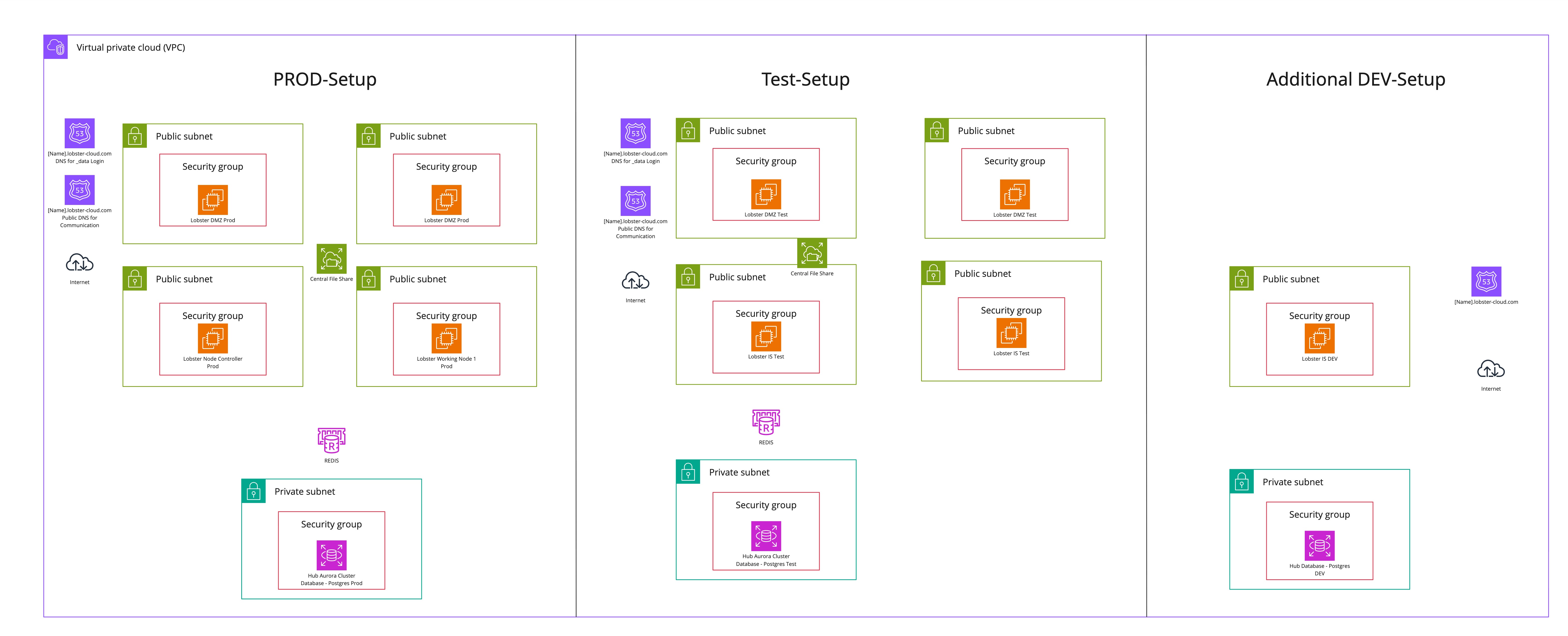
HA-Setup mit HA-Testsystem
Das folgende Diagramm zeigt eine standardmäßige Lobster Cloud High-Availability-Umgebung mit einem High-Availability-Testsystem. Sie können das High-Availability-Testsystem optional zubuchen. Das Diagramm zeigt zusätzlich ein optionales DEV-System. Das DEV-System ist nicht im Basis-Setup enthalten.
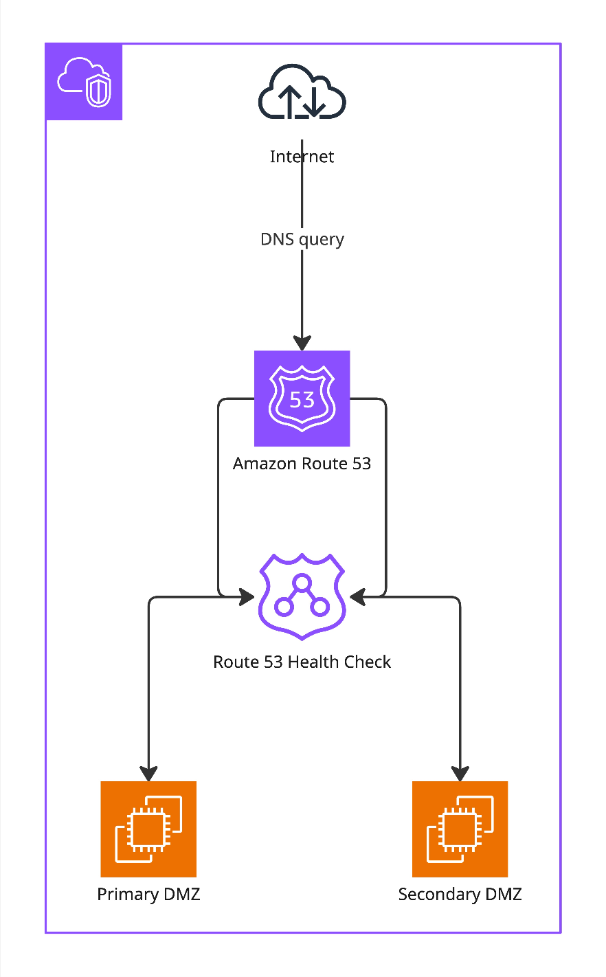
HA-DMZ-Failover: Amazon Route 53 mit Health-Checks
Das Lobster Cloud HA-Setup nutzt Route 53 mit automatisierten Health-Checks. Das sichert die kontinuierliche Verfügbarkeit Ihrer DMZ-Ebene. Route 53 löst eingehende DNS-Anfragen auf. Es überwacht kontinuierlich den Zustand der Primary DMZ und der Secondary DMZ. Der Health-Check läuft alle 30 Sekunden gegen Port 80. Wenn die Primary DMZ drei Health-Checks in Folge nicht besteht, leitet Route 53 den Datenverkehr zur Secondary DMZ um. Ein manueller Eingriff ist nicht erforderlich. Sobald die Primary DMZ die Health-Checks wieder besteht, leitet Route 53 den Datenverkehr automatisch zurück. Dieser Mechanismus erkennt und behebt den Ausfall des primären Knotens in einem vorhersehbaren Zeitrahmen.
Node-Failover: Health-Check
Die Health-Checks von Route 53 identifizieren auch intern den aktiven Node Controller. Bei Logins von außen über die DMZ ermittelt die DMZ den aktiven Node Controller. Sie leitet den Login entsprechend weiter. Einige Benutzer greifen direkt hinter der DMZ auf das interne System zu. Für sie identifizieren die Health-Checks von Route 53 den aktiven Node Controller. Sie leiten den Login korrekt weiter. In beiden Fällen hat das keinen Einfluss auf das Failover-Verhalten des Systems. Die Lobster Data Platform-Software steuert das Failover vollständig.