Die High-Availability-Architektur (HA) ist das Standard-Deployment-Modell für Kunden der Edition TRANSFORM. Sie ist auch für Kunden der Editionen SCALE und ACCELERATE als optionales Upgrade gegen Aufpreis verfügbar. Die HA-Architektur bietet ein Multi-Node-Setup mit redundanten Komponenten über alle kritischen Schichten hinweg und liefert eine garantierte Verfügbarkeit von 99,9 % pro Monat.
Überblick
Im Gegensatz zur Standardarchitektur, die auf einem einzelnen Lobster Data Platform Server basiert, verteilt die HA-Architektur die Last auch auf die Working Node(s). Jede kritische Komponente verfügt über ein redundantes Gegenstück, das bei Ausfall der primären Komponente automatisch übernehmen kann. Das System ist so konzipiert, dass ein einzelner Ausfall eines Nodes keinen vollständigen Ausfall verursacht.
Die HA-Architektur ist eine softwarebasierte Lösung. Die Lobster Data Platform Software steuert Failover und Load-Balancing auf Anwendungsebene. Die zugrunde liegende AWS-Cloud-Infrastruktur stellt die Plattform (virtuelle Maschinen, Netzwerk, Speicher) bereit, auf der das HA-System arbeitet, kontrolliert jedoch nicht die Failover-Logik auf Anwendungsebene.
Ausnahmen hiervon sind die DMZ-Server und die Datenbank. Das DMZ-Failover wird durch den AWS-DNS-Dienst über Health-Checks gesteuert. Das Datenbank-Failover wird durch den AWS-Aurora-Dienst mit automatischer Replica-Promotion gehandhabt.
Komponenten
Alle erforderlichen Informationen finden Sie unter Editions und Sizing
Die Architekturdiagramme finden Sie hier: Architekturdiagramme
Failover-Mechanismus
DMZ-Failover
Das DMZ-Failover wird auf Infrastrukturebene durch den AWS-DNS-Dienst gesteuert. Health Checks überwachen kontinuierlich den primären DMZ-Server. Wenn der primäre Server nicht mehr reagiert, leitet DNS automatisch den gesamten eingehenden Datenverkehr an den Standby-DMZ-Server um. Kein manueller Eingriff ist erforderlich.
Node-Failover
Das Node-Failover wird auf Anwendungsebene durch die Lobster Data Platform Software gesteuert. Der Node Controller und die Working Node(s) überwachen einander kontinuierlich. Fällt der Node Controller aus, erkennt der nächste Working Node in der Reihe dies und übernimmt die Verarbeitung. Sobald der Node Controller wieder online ist, übernimmt er automatisch das Failover-Handling.
Dies ist eine softwarebasierte HA-Lösung. Die Lobster-Software führt die Health Checks durch und entscheidet, wann ein Failover ausgelöst oder die Last umverteilt wird. Die Cloud-Infrastruktur stellt die passende Infrastruktur bereit, kontrolliert jedoch nicht die Failover-Logik zwischen den Nodes.
Datenbank-Failover
Das Datenbank-Failover wird durch AWS Aurora PostgreSQL gesteuert. Die primäre Datenbankinstanz verarbeitet alle Schreib- und Leseoperationen. Eine synchronisierte Replica wird im Nur-Lese-Modus vorgehalten. Fällt die primäre Instanz aus, stuft Aurora die Replica automatisch zur neuen primären Instanz hoch. Die Datenintegrität wird durch synchrone Replikation sichergestellt.
Shared File System
Die HA-Architektur erfordert ein gemeinsam genutztes Dateisystem, auf das alle Nodes gleichzeitig zugreifen können. Zwei Optionen stehen zur Verfügung:
Standard Volume (EFS)
AWS Elastic File System (EFS) ist das Standard-Dateisystem für HA-Umgebungen. Es eignet sich für Workloads, die vorwiegend größere Dateien (100 KB und mehr) verarbeiten. Alle erforderlichen Informationen finden Sie unter Editions und Sizing
EFS verwendet eine minimale Abrechnungseinheit von 4 KB pro Dateizugriff. Das bedeutet, dass selbst beim Lesen einer 1-KB-Datei 4 KB Durchsatz verbraucht werden. Bei Workloads mit vielen kleinen Dateien kann dieser Overhead den effektiven Durchsatz erheblich reduzieren.
High Volume (FSx)
AWS FSx for NetApp ONTAP ist als Upgrade für Kunden verfügbar, die große Mengen kleiner Dateien (unter 100 KB) verarbeiten. Es liefert deutlich niedrigere Latenzen und höhere IOPS als EFS. Alle erforderlichen Informationen finden Sie unter Editions und Sizing
Sizing
Die HA-Architektur ist in Sizing M und Sizing L verfügbar. Alle erforderlichen Informationen finden Sie unter Editions und Sizing
HA Neustart- und Patchingverhalten
Ausführliche Informationen zum Wartungsplan und zu Updates finden Sie hier Wartungsplan und Software-Update-Richtlinie
Info
Informationen zur Systemverfügbarkeit während Software-Updates und geplanter Wartung finden Sie unter Wartungsplan
Skalierbarkeit
Skalierungstyp | Beschreibung |
|---|---|
Horizontale Skalierung | Hinzufügen eines zusätzlichen Working Node zur Verteilung der Last auf mehr Verarbeitungsknoten. Maximal ein zusätzlicher Working Node pro Umgebung (Produktion und Test). |
Vertikale Skalierung | Upgrade von Dimensionierung M auf Dimensionierung L für erhöhte Rechen- und Speicherkapazität auf allen Nodes. |
Speicher-Skalierung | Erweiterung der Kapazität des gemeinsam genutzten Dateisystems über Storage-Erweiterungspakete. Upgrade von Standard Volume (EFS) auf High Volume (FSx) für leistungsintensive Workloads. |
Vertikale Skalierung
Ein Upgrade auf eine höhere Sizing-Stufe — beispielsweise von Sizing M auf Sizing L — erhöht die Rechen- und Speicherkapazität aller Nodes. Das Upgrade wird sequenziell, Node für Node, durchgeführt. Dabei sorgt der Failover-Mechanismus der Lobster-Software dafür, dass ein verfügbarer Node temporär zum Node Controller befördert wird und die Systemverfügbarkeit während des gesamten Vorgangs gewährleistet bleibt. Für jeden einzelnen Node ist ein kurzes Wartungsfenster erforderlich, während das Gesamtsystem durchgehend in Betrieb bleibt.
Während des sequenziellen Upgrade-Prozesses können beim Neustart einzelner Nodes und der Umverteilung des Traffics kurzzeitige Verzögerungen in der Antwortzeit auftreten. Diese sind erwartetes Verhalten und vorübergehender Natur.
Ideale Anwendungsfälle
Die HA-Architektur ist für Umgebungen konzipiert, in denen Ausfallzeiten direkte geschäftliche Auswirkungen haben:
Anwendungsfall | Beschreibung |
|---|---|
24/7-Geschäftsbetrieb | Nahezu unterbrechungsfreie Datenintegrations-Workflows für Unternehmen, die rund um die Uhr arbeiten. |
Hochvolumige Transaktionsverarbeitung | Umgebungen, die große Mengen an Transaktionen verarbeiten, bei denen selbst kurze Ausfälle erhebliche Rückstände verursachen. |
Compliance und Disaster Recovery | Organisationen mit strengen regulatorischen Anforderungen an Systemverfügbarkeit und Datenschutz. |
Geschäftskritische Integrationen | Prozesse, bei denen Partnersysteme, APIs oder automatisierte Workflows auf kontinuierliche Verfügbarkeit angewiesen sind. |
Architekturdiagramme
HA-Set-up mit Standard-Testsystem
Die folgende Abbildung zeigt ein Standard-Set-up der Lobster Cloud LDP-Hochverfügbarkeitsumgebung mit einem Standard-Testsystem. Zusätzlich ist ein mögliches DEV-System abgebildet, das im Basis-Set-up jedoch nicht enthalten ist.
.jpg)
HA-Set-up mit HA-Testsystem
Die folgende Abbildung zeigt ein Standard-Set-up der Lobster Cloud LDP-Hochverfügbarkeitsumgebung mit einem hochverfügbaren Testsystem, das optional hinzugebucht werden kann. Zusätzlich ist ein mögliches DEV-System abgebildet, das im Basis-Set-up jedoch nicht enthalten ist.
.jpg)
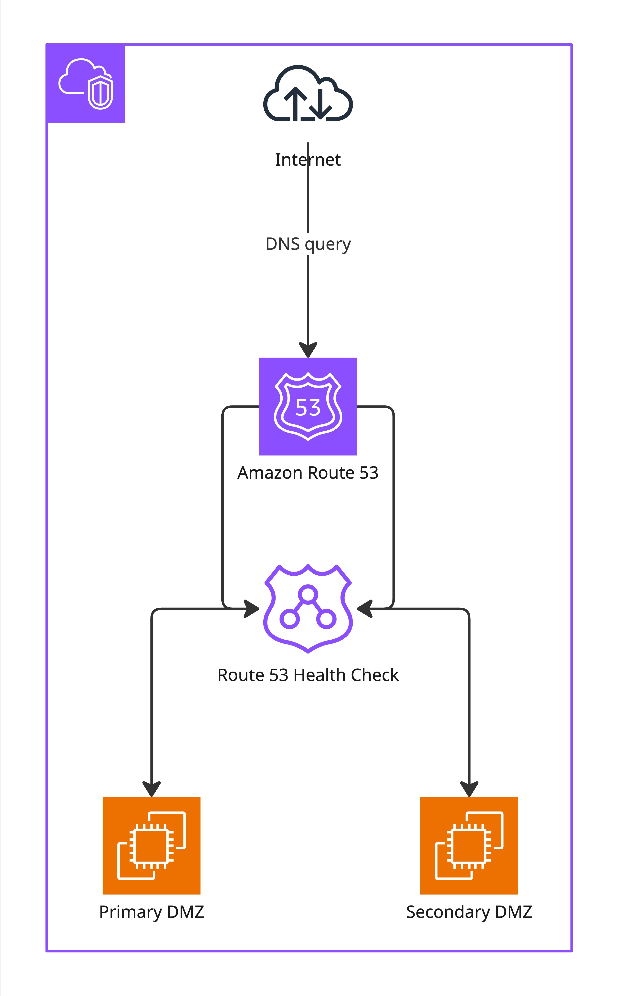
HA-DMZ-Failover – Amazon Route 53 mit Health Checks
Das Lobster Cloud HA-Set-up nutzt Amazon Route 53 in Kombination mit automatisierten Health Checks, um die kontinuierliche Verfügbarkeit Ihrer DMZ-Schicht sicherzustellen. Eingehende DNS-Anfragen werden von Route 53 aufgelöst, das gleichzeitig den Zustand der Primary DMZ und der Secondary DMZ kontinuierlich überwacht. Der Health Check wird alle 30 Sekunden über Port 80 durchgeführt. Schlägt der Health-Check der Primary-DMZ dreimal in Folge fehl, leitet Route 53 den Traffic automatisch auf die Secondary-DMZ um – ohne manuellen Eingriff. Sobald die Primary DMZ wieder erreichbar ist und die Health Checks erfolgreich besteht, wird der Traffic automatisch zurückgeleitet. Dieser Mechanismus stellt sicher, dass ein Ausfall des primären Knotens innerhalb eines definierten und vorhersehbaren Zeitrahmens erkannt und kompensiert wird.
Node-Failover—Health-Check
Derselbe Route-53-Health-Check-Mechanismus wird intern auch genutzt, um den aktiven Node Controller zu ermitteln. Bei einer Anmeldung von außen über die DMZ ermittelt die DMZ den aktiven Node-Controller und leitet die Anmeldung entsprechend weiter. Für Benutzer, die direkt hinter der DMZ auf das interne System zugreifen, wird der aktive Node Controller über den Route 53-Health-Check ermittelt und die Anmeldung entsprechend weitergeleitet. In beiden Fällen hat dies keinen Einfluss auf das Failover-Verhalten des Systems, das vollständig durch die Lobster-Software gesteuert wird.